1. 后端
1.1 后端目录
graph LR
A["src/main/java/com/xxx/xxxSystem/"]:::root
%% 一级目录
A --> B_common["common/"]:::pkg1
A --> B_config["config/"]:::pkg2
A --> B_controller["controller/"]:::pkg3
A --> B_enums["enums/"]:::pkg4
A --> B_exception["exception/"]:::pkg5
A --> B_feignClient["feignClient/"]:::pkg6
A --> B_mapper["mapper/"]:::pkg7
A --> B_pojo["pojo/"]:::pkg8
A --> B_service["service/"]:::pkg9
A --> B_utils["utils/"]:::pkg10
%% common 下
B_common --> C_MyConstants["MyConstants.java<br/><small>常量定义</small>"]:::pkg1
%% config 下
B_config --> C_FeignConfig["FeignConfig.java<br/><small>给 Spring Cloud OpenFeign 客户端统一配置请求超时和重定向行为</small>"]:::pkg2
B_config --> C_GlobalExceptionConfig["GlobalExceptionConfig.java<br/><small>Spring Boot全局异常处理器,用于捕获所有未处理的异常,记录错误日志,并在生产环境通过RocketMQ发送异常信息到消息队列,同时返回统一格式的错误响应。</small>"]:::pkg2
B_config --> C_MybatisFlexConfig["MybatisFlexConfig.java"]:::pkg2
%% controller 下
B_controller --> C_AppInfoController["AppInfoController.java"]:::pkg3
%% enums 下
B_enums --> C_TestCaseEditStatusEnum["TestCaseEditStatusEnum.java"]:::pkg4
%% exception 下
B_exception --> C_MyException["MyException.java"]:::pkg5
%% feignClient 下
B_feignClient --> C_FileServiceCenterBackEndClient["FileServiceCenterBackEndClient.java"]:::pkg6
%% mapper 下
B_mapper --> C_AppInfoMapper["AppInfoMapper.java"]:::pkg7
%% pojo 下
B_pojo --> C_dao["dao/"]:::pkg8
B_pojo --> C_dto["dto/"]:::pkg8
B_pojo --> C_entity["entity/"]:::pkg8
B_pojo --> C_vo["vo/"]:::pkg8
B_pojo --> C_BaseResult["BaseResult.java"]:::pkg8
%% service 下
B_service --> C_impl["impl/"]:::pkg9
C_impl --> D_AppInfoServiceImpl["AppInfoServiceImpl.java"]:::pkg9
B_service --> C_AppInfoService["AppInfoService.java"]:::pkg9
%% utils 下
B_utils --> C_MyDateUtils["MyDateUtils.java"]:::pkg10
B_utils --> C_MyIpUtils["MyIpUtils.java"]:::pkg10
%% 样式定义
classDef root fill:#333,stroke:#000,color:#fff,font-size:16px;
classDef pkg1 fill:#fde2e2,stroke:#fcc, color:#900;
classDef pkg2 fill:#e0f7fa,stroke:#b2ebf2, color:#006064;
classDef pkg3 fill:#f3e5f5,stroke:#e1bee7, color:#4a148c;
classDef pkg4 fill:#fff3e0,stroke:#ffe0b2, color:#e65100;
classDef pkg5 fill:#e8f5e9,stroke:#c8e6c9, color:#1b5e20;
classDef pkg6 fill:#f1f8e9,stroke:#dcedc8, color:#33691e;
classDef pkg7 fill:#eceff1,stroke:#cfd8dc, color:#37474f;
classDef pkg8 fill:#fffde7,stroke:#fff9c4, color:#f57f17;
classDef pkg9 fill:#e8eaf6,stroke:#c5cae9, color:#283593;
classDef pkg10 fill:#fbe9e7,stroke:#ffccbc, color:#bf360c;
classDef file fill:#ffffff,stroke:#aaa, color:#333,font-size:12px;
1.1.1 POJO(Plain Ordinary Java Object):DAO、VO、DTO和实体类
简单的Java对象,实际就是普通JavaBeans
1.1.1.1 DAO(Data Access Object)
数据访问对象,DAO 是用于访问数据库的对象。它通常包含了对数据库的 CRUD(创建、读取、更新、删除)操作。DAO 与数据库直接相关,用于封装数据库操作的细节,以便其他部分的代码可以通过 DAO 来访问数据库。
在大部分生产环境中,dao对应mapper,而entity对应下方的dao
模板(以MybatisFlex为例)待补充关联查询
package com.xxx.UserBusiness.pojo.dao;
import com.fasterxml.jackson.annotation.JsonFormat;
import com.mybatisflex.annotation.Id;
import com.mybatisflex.annotation.KeyType;
import com.mybatisflex.annotation.Table;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.time.LocalDateTime;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
@Table("xxxx")
public class PermissionPointMapDao {
/** 主键自增长-ID */
@Id(keyType = KeyType.Auto)
private Integer id;
/** 权限点id */
private Integer permissionPointId;
/** 权限点描述 */
private String permissionPointDescription;
/** 路由路径信息 */
private String routingPathInfo;
/** 创建时间 */
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime createTime;
/** 更新时间 */
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime updateTime;
}1.1.1.2 VO(View Object)
视图对象,VO 通常用于将从数据库中检索的数据封装为对象,然后将其传递给其他部分的代码。VO 通常与数据库中的表字段对应,用于表示数据库中的数据。
1.1.1.3 DTO(Data Transfer Object)
数据传输对象,DTO 用于在Service层和Controller层之间传输数据,特别是在前后端分离的场景中。它通常用于接收接口传入的参数,DTO的字段通常与Entity不完全相同,它根据前端的需求进行定制。(传入一两个参数可以接口处直接定义,如果是多个参数需要放在dto里)
1.1.1.4 Entity
实体类通常指的是与数据库表相对应的类。它通常包含了表的字段和与之相关的方法。实体类通常用于表示数据库中的数据,并且通常与数据库中的表字段一一对应。(公司内主要用于定义需要用的字段,和Dao是反着来的)
1.1.2 CorsConfig
1.1.3 BaseResults
package com.xxx.xxxSystem.pojo;
import com.fasterxml.jackson.annotation.JsonInclude;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* AllArgsConstructor 为当前类生成一个 全参构造器
* NoArgsConstructor 为当前类生成一个 空参构造器
* Data 为每个字段生成 getXxx() / setXxx(...)、toString()、equals() 和 hashCode() 方法
* JsonInclude(JsonInclude.Include.NON_NULL) 在将对象序列化成 JSON 时,排除所有值为 null 的字段
* */
@AllArgsConstructor
@JsonInclude(JsonInclude.Include.NON_NULL)
@Data
@NoArgsConstructor
public class BaseResult {
public static final Integer STATUS_SUCCESS = 200;
public static final Integer STATUS_FAILED = -1;
public static final String MSG_OK = "OK";
/** 响应业务状态 */
private Integer code;
/** 响应消息 */
private String msg;
/** 响应中的数据 */
private Object data;
/**
* 返回失败消息
*
* @param message 消息
* @return {@link BaseResult}
*/
public static BaseResult returnFailedWithMessage(String message) {
return new BaseResult(BaseResult.STATUS_FAILED, message, null);
}
/**
* 返回失败状态,没有消息
*
* @return {@link BaseResult}
*/
public static BaseResult returnFailedStatusWithNoMessage() {
return new BaseResult(BaseResult.STATUS_FAILED, null, null);
}
/**
* 返回成功消息 OK
*
* @return {@link BaseResult}
*/
public static BaseResult returnSuccessWithMessageOk() {
return new BaseResult(BaseResult.STATUS_SUCCESS, BaseResult.MSG_OK, null);
}
/**
* 返回成功消息和数据
*
* @param data 数据
* @return {@link BaseResult}
*/
public static BaseResult returnSuccessMessageOkAndData(Object data) {
return new BaseResult(BaseResult.STATUS_SUCCESS, BaseResult.MSG_OK, data);
}
}
BaseResults的局限
按照上述的BaseResults只能用Base64将文件放入data中传输,不适合大文件传输;或者使用构造静态资源 URL 的方式。这里介绍一些其他[传递文件的方法](#1.9.6 Java传递文件的方式),以图片为例,推荐使用字节流方式。
推荐解决方法:构造静态资源 URL
需要注意,如果后端开启了JwtToken验证,需要将URL返回给前端,前端通过axios发送token请求头,并以Blob响应形式下载文件内容。如果域名被设置了SSL加密,后端返回URL时还需要加https。
静态资源通过Blob要用GET方法下载
1.1.4 Controller
package com.xxx.xxxSystem.controller;
import com.xxx.xxxSystem.pojo.BaseResult;
import com.xxx.xxxSystem.pojo.dto.*;
import com.xxx.xxxSystem.service.AppInfoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import javax.validation.Valid;
import javax.validation.constraints.NotEmpty;
import javax.validation.constraints.NotNull;
import java.util.List;
@RestController
@RequestMapping(value = "/xxxApi")
@Validated
@Slf4j
public class XxxController {
@Resource
private XxxService xxxService;
/**
* 创建新应用程序信息
*
* @param createNewXxxDto 创建新应用程序信息dto
* @return {@link BaseResult }
*/
@PostMapping(value = "/create/newXxx")
public BaseResult createNewXxx(@Valid CreateNewXxxDto createNewXxxDto) {
return xxxService.createNewXxx(createNewXxxDto);
}1.1.5 Service
package com.xxx.XxxSystem.service;
import com.xxx.XxxSystem.pojo.BaseResult;
import com.xxx.XxxSystem.pojo.dto.*;
import java.util.List;
public interface XxxService {
BaseResult createNewXxx(CreateNewXxxDto createNewXxxDto);
}1.1.6 ServiceImpl
package com.xxx.AutoTestCaseSystem.service.impl;
import com.mybatisflex.core.paginate.Page;
import com.mybatisflex.core.query.QueryChain;
import com.mybatisflex.core.query.QueryWrapper;
import com.mybatisflex.core.update.UpdateChain;
import com.mysql.cj.util.StringUtils;
import com.xxx.AutoTestCaseSystem.common.MyConstants;
import com.xxx.AutoTestCaseSystem.feignClient.FileServiceCenterBackEndClient;
import com.xxx.AutoTestCaseSystem.mapper.AppInfoMapper;
import com.xxx.AutoTestCaseSystem.mapper.TestCaseDetailMapper;
import com.xxx.AutoTestCaseSystem.mapper.TestMethodMapper;
import com.xxx.AutoTestCaseSystem.mapper.TestSceneMapToCaseMapper;
import com.xxx.AutoTestCaseSystem.pojo.BaseResult;
import com.xxx.AutoTestCaseSystem.pojo.dao.*;
import com.xxx.AutoTestCaseSystem.pojo.dto.*;
import com.xxx.AutoTestCaseSystem.pojo.dto.fileSystem.DeleteFileDto;
import com.xxx.AutoTestCaseSystem.pojo.entity.DifferentRoleUserList;
import com.xxx.AutoTestCaseSystem.pojo.entity.UserInfoLiteEntity;
import com.xxx.AutoTestCaseSystem.pojo.vo.AppInfoVo;
import com.xxx.AutoTestCaseSystem.service.AppInfoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.util.List;
import static com.xxx.AutoTestCaseSystem.enums.TestCaseEditStatusEnum.ABANDON_CHECK_PASS;
import static com.xxx.AutoTestCaseSystem.pojo.dao.table.AppInfoDaoTableDef.APP_INFO_DAO;
@Slf4j
@Service
public class AppInfoServiceImpl implements AppInfoService {
@Resource
private AppInfoMapper appInfoMapper;
@Override
@Transactional(rollbackFor = Exception.class)
public BaseResult createNewAppInfo(CreateNewAppInfoDto createNewAppInfoDto) {
List<AppInfoDao> appInfoDaoList = QueryChain.of(AppInfoDao.class)
.eq(AppInfoDao::getAppType, createNewAppInfoDto.getAppType())
.list();
boolean ifExist = appInfoDaoList.stream()
.map(AppInfoDao::getPackageName)
.anyMatch(name -> name.equals(createNewAppInfoDto.getPackageName()));
if (ifExist) {
String errMsg = "createNewAppInfo: " + "xxx已存在,请检查后重试";
log.error(errMsg);
return BaseResult.returnFailedWithMessage(errMsg);
}
AppInfoDao appInfoDao = new AppInfoDao();
appInfoDao
.setAppName(createNewAppInfoDto.getAppName())
.setPackageName(createNewAppInfoDto.getPackageName());
appInfoMapper.insertSelective(appInfoDao);
return BaseResult.returnSuccessWithMessageOk();
}1.2 SQL配置与使用
1.2.1 连接
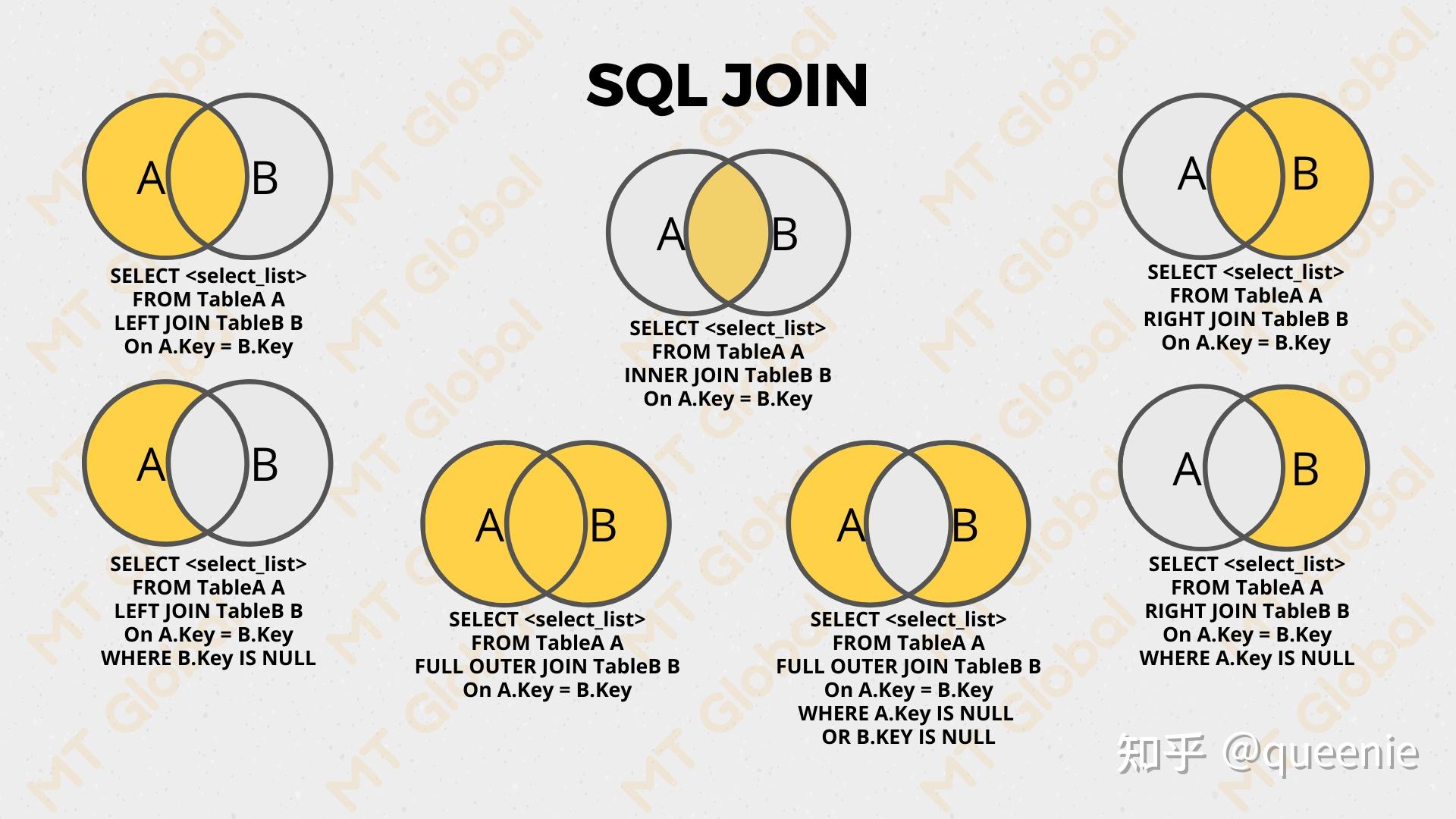
- 内连接(JOIN / INNER JOIN)
- 只保留两张表都能匹配上的行。
- MyBatis‑Flex:
.innerJoin(OtherDao.class).on(...)或者只写join
- 左外连接(LEFT OUTER JOIN / LEFT JOIN)
- 保留左表的所有行,右表匹配不到的列填
NULL。 - MyBatis‑Flex:
.leftJoin(OtherDao.class).on(...)
- 保留左表的所有行,右表匹配不到的列填
- 右外连接(RIGHT OUTER JOIN / RIGHT JOIN)
- 保留右表的所有行,左表匹配不到的列填
NULL。 - MyBatis‑Flex:
.rightJoin(OtherDao.class).on(...)
- 保留右表的所有行,左表匹配不到的列填
- 全外连接(FULL OUTER JOIN / FULL JOIN)
- 左右两表的所有行都保留,匹配不到的列填
NULL。 - MySql原生不支持这种写法,PostgreSql支持
- MyBatis‑Flex:
.fullJoin(OtherDao.class).on(...)
- 左右两表的所有行都保留,匹配不到的列填
其他加where的如下图所示都是上面连接的变种,即加过滤条件
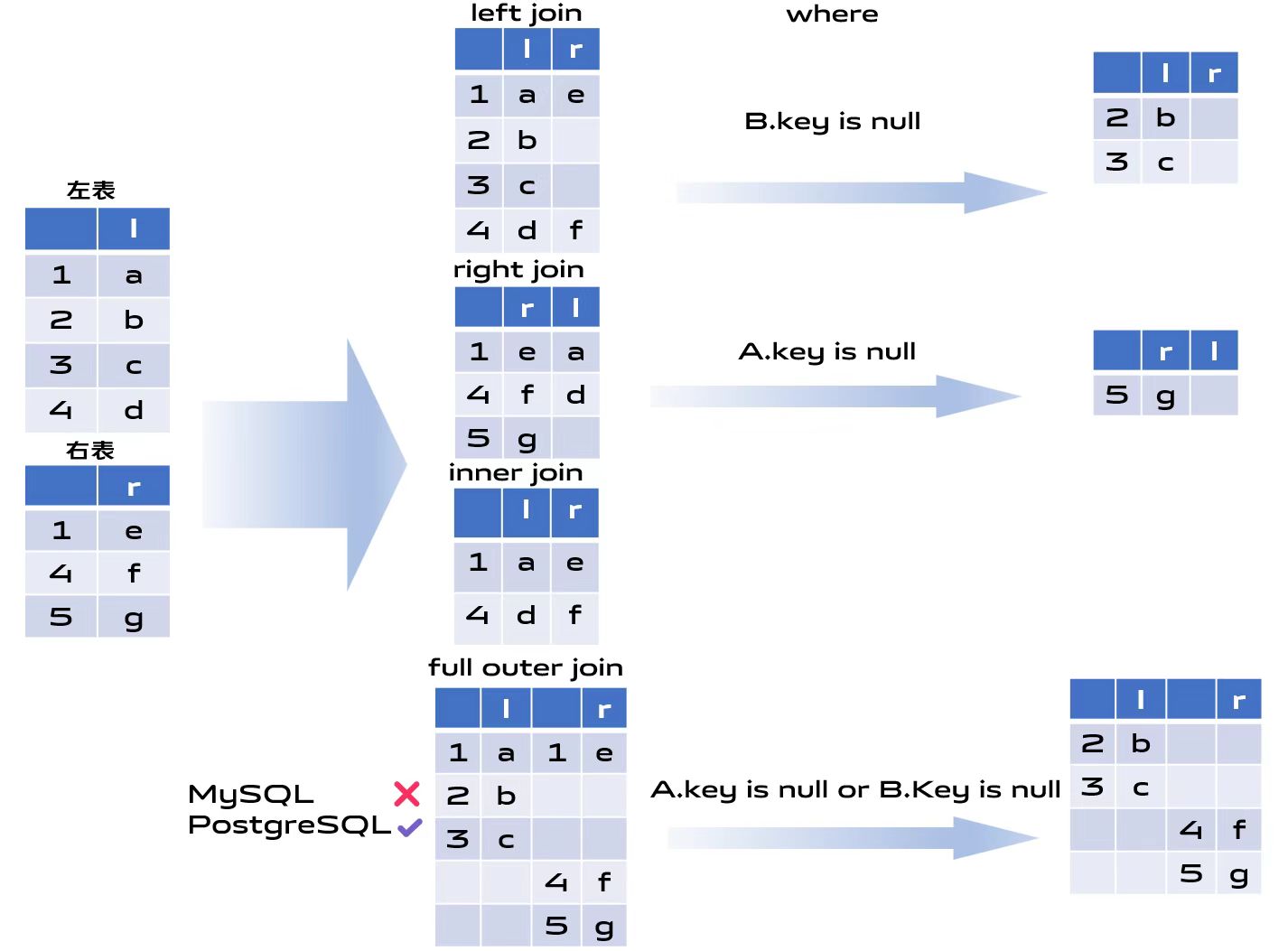
https://zhuanlan.zhihu.com/p/30757775036
交叉连接(CROSS JOIN)
- 含义:将左表和右表中的每一行两两配对,返回笛卡尔积。
- 结果行数 = 左表行数 × 右表行数。
- MyBatis‑Flex:
.crossJoin(OtherDao.class).on(...)
自然连接(NATURAL JOIN)
- 含义:根据同名列按照内连接自动匹配。
- 使用方法:只能在sql语句里写,MybatisFlex不支持
SELECT *
FROM tableA
NATURAL JOIN tableB;- 自连接(Self‑Join)
- 含义:将一张表“复制”成两个逻辑实体表(通过不同别名),然后在它们之间做连接。
- 使用方法:只能用其他join实现相同的效果
SELECT e.id AS emp_id,
e.name AS emp_name,
m.id AS mgr_id,
m.name AS mgr_name
FROM employee AS e
LEFT JOIN employee AS m
ON e.manager_id = m.id;- Union
- 含义:集合操作符,用于把两个或多个
SELECT语句的结果“垂直”合并成一个结果集。 - 使用方法:
- 含义:集合操作符,用于把两个或多个
SELECT 列列表
FROM 表1
WHERE 条件1
UNION
SELECT 列列表
FROM 表2
WHERE 条件2;- 结果:
| id | val |
|---|---|
| 1 | e |
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | f |
| 4 | d |
| 5 | g |
1.2.2 数据库连接池
配置
spring:
...
datasource:
url: jdbc:mysql://IP:3306/xxl_job?useSSL=false&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxx
password: xxx
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
hikari:
# 连接池的最小连接数,低于这个数会补充
minimum-idle: 10
# 连接池的最大连接数
maximum-pool-size: 30
# 默认自动提交事务
auto-commit: true
# 空闲连接 30s 没用会被回收
idle-timeout: 30000
# 线程池名字(方便日志里区分)
pool-name: HikariCP
# 连接最长存活时间(15分钟)
max-lifetime: 900000
# 获取连接的最大等待时间(10秒)
connection-timeout: 10000
# 用来检测连接是否可用
connection-test-query: SELECT 1
# 校验连接的超时时间
validation-timeout: 1000com.zaxxer.hikari.HikariDataSource 是什么?
它是 HikariCP 的数据源类。
- HikariCP 是目前 Spring Boot 默认使用的数据库连接池实现(性能非常好)。
HikariDataSource就是它的核心类,Spring Boot 会用它来管理数据库连接,它是 Spring Boot 默认推荐的连接池(比 Druid、C3P0、Tomcat JDBC 都快)。
连接池的作用
数据库连接很“贵”,频繁开关连接会很慢,连接池可以提高性能。
- 预先创建一批连接(比如 10 个)
- 程序要用时,直接从池里取,不用再跟数据库“重新握手”
- 用完再放回池子,下一个线程可以复用
Alibaba Druid
1.2.3 性能优化
SQLsession
索引
是否唯一?
1.2.4 SQL注入
在代码编写过程中,直接暴露SQL语句的地方,不能直接传递变量。
- 风险来自:
"DISTINCT " + columnName这种把SQL 结构(列名/关键字)用字符串拼出来 - 不是所有拼接都危险:拼接值如果走
#{}参数化就安全,但列名永远没法参数化,只能拼:
qw.select("DISTINCT " + columnName)只要 columnName 是外部输入,就必须做你上面那种白名单校验,否则就可能:
- 传不存在列 → 直接 500
- 传恶意片段 → 注入(是否能成功取决于驱动/数据库是否允许多语句等,但不能赌)
用通用方法 + 条件值参数(安全)
比如 MyBatis-Plus 这种:
LambdaQueryWrapper<UsersInfoEntity> qw = Wrappers.lambdaQuery();
qw.eq(UsersInfoEntity::getAsset, assetValue);
usersInfoMapper.selectList(qw);这里的 assetValue 会走参数化(本质 #{}),属于值参数,一般不产生注入问题。
1.3 Mybatis
1.3.1 SqlSession
SqlSession 这个概念来自 MyBatis(MyBatis-Flex、MyBatis-Plus 也是在它之上扩展的)。它的作用,可以简单理解为:
SqlSession就是 和数据库交互的会话对象,你通过它来执行 SQL语句(增删改查)。- 类似于 JDBC 里的
Connection + Statement的结合体。 - 它不是线程安全的,每次使用都应该获取一个新的,使用完要关闭。
1.3.1.1 主要功能
selectOne/selectList:查询insert:插入update:更新delete:删除getMapper(Class<T> type):获取一个 Mapper 接口的代理(推荐用这个方式调用,而不是直接写 SQL ID)
在 SpringBoot 集成 MyBatis 后,一般不用你手动管理 SqlSession 了:
- Spring 会把
SqlSession封装成SqlSessionTemplate(线程安全的),交给 IOC 容器管理。 - 你只需要注入
Mapper接口就能用。
1.3.1.2 实战
我们可以利用SqlSession的功能进行一些批量操作。
例如,我们可以先将逐条生成 SQL,但不立刻发给数据库;而是先放到 JDBC 驱动的 batch 缓冲区。在循环500次后批量commit。结束要手动关闭
@Override
@Transactional(rollbackFor = Exception.class)
public BaseResult deleteCaseInfoByCasIdList(List<Integer> caseIdList) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false);
CaseCollectionDetailMapper batchMapper = sqlSession.getMapper(CaseCollectionDetailMapper.class);
try {
for (int i = 0; i < caseIdList.size(); i++) {
int caseIdIndex = caseIdList.get(i);
LambdaQueryWrapper<CaseCollectionDetailDao> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(CaseCollectionDetailDao::getCaseId, caseIdIndex);
// 1 查询原案例信息,删除原文件信息
CaseCollectionDetailDao caseCollectionDetailDao = batchMapper.selectOne(lambdaQueryWrapper);
if (caseCollectionDetailDao == null) {
throw new MyException(MyConstants.MSG_DATA_SEARCH_RESULT_NULL);
}
DeleteFileDto deleteFileDto = new DeleteFileDto();
deleteFileDto.setBusinessPlatform(MyConstants.STRING_BUSINESS_PLATFORM_CASE_COLLECTION);
List<String> oldFileTidOfBeforeModifyTidList = new ArrayList<>();
oldFileTidOfBeforeModifyTidList.add(caseCollectionDetailDao.getFileTidBeforeModify());
// 2 调用接口删除对应的文件
deleteFileDto.setBusinessTidList(oldFileTidOfBeforeModifyTidList);
BaseResult fileBeforeModifyDeleteResult = fileServiceCenterBackEndClient.deleteBatchFilesByTidList(deleteFileDto);
if (BaseResult.STATUS_FAILED.equals(fileBeforeModifyDeleteResult.getStatus())) {
throw new MyException("fileBeforeModify delete failed, msg = " + fileBeforeModifyDeleteResult.getMsg());
}
List<String> oldFileTidOfAfterModifyTidList = new ArrayList<>();
oldFileTidOfAfterModifyTidList.add(caseCollectionDetailDao.getFileTidAfterModify());
deleteFileDto.setBusinessTidList(oldFileTidOfAfterModifyTidList);
BaseResult fileAfterModifyDeleteResult = fileServiceCenterBackEndClient.deleteBatchFilesByTidList(deleteFileDto);
if (BaseResult.STATUS_FAILED.equals(fileAfterModifyDeleteResult.getStatus())) {
throw new MyException("fileAfterModify delete failed, msg = " + fileAfterModifyDeleteResult.getMsg());
}
// 3 删除数据
batchMapper.delete(lambdaQueryWrapper);
if (i % 500 == 499) {
//每500条提交一次防止内存溢出
sqlSession.commit();
sqlSession.clearCache();
}
}
} catch (Exception e) {
log.error("deleteCaseInfoByCasIdList -- operate batch error, e = ", e);
sqlSession.rollback();
sqlSession.close();
return BaseResult.returnFailedWithMessage(MyConstants.MSG_DATA_DELETE_BATCH_FAILS);
} finally {
sqlSession.commit();
sqlSession.clearCache();
sqlSession.close();
}
return BaseResult.returnSuccessWithMessageOk();
}1.3.2 MybatisFlex
Config
package com.xxx.AutoTestCaseSystem.config;
import com.mybatisflex.core.FlexGlobalConfig;
import com.mybatisflex.core.mybatis.FlexConfiguration;
import com.mybatisflex.spring.boot.ConfigurationCustomizer;
import com.mybatisflex.spring.boot.MyBatisFlexCustomizer;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@MapperScan("com.xxx.AutoTestCaseSystem.mapper")
public class MybatisFlexConfig implements ConfigurationCustomizer, MyBatisFlexCustomizer {
@Override
public void customize(FlexConfiguration flexConfiguration) {
// 开启驼峰映射 原始配置中,默认配置开关状态:true
flexConfiguration.setMapUnderscoreToCamelCase(true);
// 开启log日志
// flexConfiguration.setLogImpl(StdOutImpl.class);
}
@Override
public void customize(FlexGlobalConfig flexGlobalConfig) {
}
}Join
MybatisFlex具有和MybatisPlusJoin(MybatisPlus的社区扩展)类似的能力,支持join。在不写select且不指定查询哪张表的情况下默认查询所有
关联查询
@RelationOneToOne(selfField = "commitId", targetField = "userUuid", targetTable = "user_info", valueField = "deptCode")
private String deptCode;相当于左连接,根据当前表的commitId == user_1_basic_info表的userUuid进行连接,查询deptCode,表面是要查提交人的部门代码。需要在前面写好.withRelations()或者.paginateWithRelationsAs。
逻辑删
MybatisFlex也有逻辑删功能,用法与plus略有不同
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
@Table("table_name")
public class VideoProblemDetailDao {
/** id - 主键自增长 */
@Id(keyType = KeyType.Auto)
private Integer id;
/** 默认0, 逻辑删除状态(归档用):1-已删除;0-未删除 */
@Column(isLogicDelete = true)
private Integer isDeleted;
}查询时,默认查未逻辑删的内容,如果需要全查需要区分。
List<Dao> DaoList = LogicDeleteManager.execWithoutLogicDelete(() ->
QueryChain.of(Dao.class).list()
);UpdateChain
QueryChain不能用于Dao更改,需要用UpdateChain处理,或者用Mapper调用自定义或者update等通用方法。
乐观锁
类似Plus,Flex也有乐观锁开启的方法:
@Column(version = true)
private Integer dataVersion;update数据时,如果有两个线程同时更新,当有一个线程已经将版本+1,另一个线程就不能再更新了。
| 时间 | 线程A | 线程B |
|---|---|---|
| T1 | 读到 data_version=5 | 读到 data_version=5 |
| T2 | 改字段并提交 → 版本从 5 变 6 | |
| T3 | 改字段并提交 → WHERE 条件要求 data_version=5,但现在是6 → 更新失败 |
如果需要在乐观锁冲突时回滚,需要自己抛异常
实战
package com.xxx.AnimationOpinionControlSystem.service.impl;
import com.mybatisflex.core.paginate.Page;
import com.mybatisflex.core.query.QueryChain;
import com.xxx.AnimationOpinionControlSystem.pojo.BaseResult;
import com.xxx.AnimationOpinionControlSystem.pojo.dao.OpinionClassifiedResultDao;
import com.xxx.AnimationOpinionControlSystem.pojo.dao.OpinionDetailDao;
import com.xxx.AnimationOpinionControlSystem.pojo.dao.OpinionThresholdInfoDao;
import com.xxx.AnimationOpinionControlSystem.pojo.dto.OpionionPreWarning.QueryPreWarningInfoDto;
import com.xxx.AnimationOpinionControlSystem.pojo.vo.OpinionPreWarningVo;
import com.xxx.AnimationOpinionControlSystem.service.OpinionPreWarningService;
import com.xxx.AnimationOpinionControlSystem.utils.MyDateUtils;
import com.xxx.AnimationOpinionControlSystem.utils.OpinionDataUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.Arrays;
import java.util.Collections;
import java.util.Date;
import java.util.List;
import static com.mybatisflex.core.query.QueryMethods.count;
@Slf4j
@Service
public class OpinionPreWarningServiceImpl implements OpinionPreWarningService {
@Resource
private OpinionDataUtils opinionDataUtils;
@Override
public BaseResult queryImportantOpinionByMultiConditions(QueryPreWarningInfoDto queryPreWarningInfoDto) {
Date feedbackStartDate = MyDateUtils.timestampStringToDate(queryPreWarningInfoDto.getFeedbackStartDate());
Date feedbackEndDate = MyDateUtils.timestampStringToDate(queryPreWarningInfoDto.getFeedbackEndDate());
if (feedbackStartDate == null || feedbackEndDate == null) {
String errorMsg = "查询时间解析结果为null。" + "queryPreWarningInfoDto = " + queryPreWarningInfoDto;
log.error(errorMsg);
return BaseResult.returnFailedWithMessage(errorMsg);
}
boolean queryAllList = queryPreWarningInfoDto.getWhetherQueryAllList() != null && queryPreWarningInfoDto.getWhetherQueryAllList() == 1;
List<Integer> opinionIdList = opinionDataUtils.getOpinionIdListByFeedbackDateRange(feedbackStartDate, feedbackEndDate);
if (opinionIdList == null || opinionIdList.isEmpty()) {
if (queryAllList) {
return BaseResult.returnSuccessMessageOkAndData(Collections.<OpinionPreWarningVo>emptyList());
} else {
return BaseResult.returnSuccessMessageOkAndData(new Page<OpinionPreWarningVo>(queryPreWarningInfoDto.getPageIndex(), queryPreWarningInfoDto.getPageSize()));
}
}
int opinionPreWarningType = queryPreWarningInfoDto.getOpinionPreWarningType();
int opinionThresholdType;
switch (opinionPreWarningType) {
case 1:
opinionThresholdType = 2;
break;
case 2:
opinionThresholdType = 1;
break;
case 3:
opinionThresholdType = 3;
break;
default:
opinionThresholdType = opinionPreWarningType;
}
Integer opinionThreshold = QueryChain.of(OpinionThresholdInfoDao.class)
.select(OpinionThresholdInfoDao::getThresholdValue)
.eq(OpinionThresholdInfoDao::getId, opinionThresholdType)
.oneAs(Integer.class);
if (opinionPreWarningType == 3 && opinionThreshold != null) {
Date currentDate = feedbackStartDate;
boolean thresholdExceeded = true;
while (!currentDate.after(feedbackEndDate)) {
Long dayCount = QueryChain.of(OpinionClassifiedResultDao.class)
.in(OpinionClassifiedResultDao::getOpinionId, opinionIdList)
.leftJoin(OpinionDetailDao.class)
.on(OpinionDetailDao::getOpinionId, OpinionClassifiedResultDao::getOpinionId)
.eq(OpinionDetailDao::getFeedbackDate, currentDate)
.count();
if (dayCount < opinionThreshold) {
thresholdExceeded = false;
break;
}
currentDate = new Date(currentDate.getTime() + 24 * 60 * 60 * 1000);
}
if (!thresholdExceeded) {
if (queryAllList) {
return BaseResult.returnSuccessMessageOkAndData(Collections.<OpinionPreWarningVo>emptyList());
} else {
return BaseResult.returnSuccessMessageOkAndData(
new Page<OpinionPreWarningVo>(queryPreWarningInfoDto.getPageIndex(), queryPreWarningInfoDto.getPageSize())
);
}
}
}
QueryChain<OpinionClassifiedResultDao> opinionClassifiedResultGroupQueryChain = QueryChain.of(OpinionClassifiedResultDao.class)
.in(OpinionClassifiedResultDao::getOpinionId, opinionIdList)
.select(OpinionClassifiedResultDao::getOsVersion)
.select(OpinionClassifiedResultDao::getMainCategoryId)
.select(OpinionClassifiedResultDao::getLevelOneCategoryPk)
.select(OpinionClassifiedResultDao::getLevelTwoCategoryPk)
.select(OpinionClassifiedResultDao::getClassifiedResultId)
.select(count().as("opinionCount"))
.in(OpinionClassifiedResultDao::getOpinionType, Arrays.asList(1, 4))
.groupBy(OpinionClassifiedResultDao::getMainCategoryId)
.groupBy(OpinionClassifiedResultDao::getLevelOneCategoryPk)
.groupBy(OpinionClassifiedResultDao::getLevelTwoCategoryPk)
.groupBy(OpinionClassifiedResultDao::getOsVersion)
.having(count().ge(opinionThreshold));
if (queryPreWarningInfoDto.getOpinionPreWarningType() == 1) {
// 单日重点舆情考虑VIP和大v反馈
opinionClassifiedResultGroupQueryChain.leftJoin(OpinionDetailDao.class)
.on(OpinionDetailDao::getOpinionId, OpinionClassifiedResultDao::getOpinionId)
.in(OpinionDetailDao::getFeedbackChannel, Arrays.asList(2, 7))
.select(OpinionDetailDao::getFeedbackChannel)
.groupBy(OpinionDetailDao::getFeedbackChannel);
}
if (queryAllList) {
List<OpinionPreWarningVo> opinionPreWarningVoList = opinionClassifiedResultGroupQueryChain
.withRelations()
.listAs(OpinionPreWarningVo.class);
for (OpinionPreWarningVo opinionPreWarningVo : opinionPreWarningVoList) {
opinionPreWarningVo.setOpinionThreshold(opinionThreshold);
List<String> originalOpinionLinkList = QueryChain.of(OpinionClassifiedResultDao.class)
.eq(OpinionClassifiedResultDao::getClassifiedResultId, opinionPreWarningVo.getClassifiedResultId())
.select(OpinionDetailDao::getOriginalOpinionLink)
.leftJoin(OpinionDetailDao.class)
.on(OpinionDetailDao::getOpinionId, OpinionClassifiedResultDao::getOpinionId)
.listAs(String.class);
opinionPreWarningVo.setOriginalOpinionLinkList(originalOpinionLinkList);
List<Integer> ids = QueryChain.of(OpinionClassifiedResultDao.class)
.eq(OpinionClassifiedResultDao::getClassifiedResultId, opinionPreWarningVo.getClassifiedResultId())
.select(OpinionClassifiedResultDao::getOpinionId)
.listAs(Integer.class);
opinionPreWarningVo.setOpinionIdList(ids);
}
return BaseResult.returnSuccessMessageOkAndData(opinionPreWarningVoList);
} else {
Page<OpinionPreWarningVo> opinionPreWarningVoPage = opinionClassifiedResultGroupQueryChain
.withRelations()
.pageAs(new Page<>(queryPreWarningInfoDto.getPageIndex(), queryPreWarningInfoDto.getPageSize()), OpinionPreWarningVo.class);
for (OpinionPreWarningVo opinionPreWarningVo : opinionPreWarningVoPage.getRecords()) {
opinionPreWarningVo.setOpinionThreshold(opinionThreshold);
List<String> originalOpinionLinkList = QueryChain.of(OpinionClassifiedResultDao.class)
.eq(OpinionClassifiedResultDao::getClassifiedResultId, opinionPreWarningVo.getClassifiedResultId())
.select(OpinionDetailDao::getOriginalOpinionLink)
.leftJoin(OpinionDetailDao.class)
.on(OpinionDetailDao::getOpinionId, OpinionClassifiedResultDao::getOpinionId)
.listAs(String.class);
opinionPreWarningVo.setOriginalOpinionLinkList(originalOpinionLinkList);
List<Integer> ids = QueryChain.of(OpinionClassifiedResultDao.class)
.eq(OpinionClassifiedResultDao::getClassifiedResultId, opinionPreWarningVo.getClassifiedResultId())
.select(OpinionClassifiedResultDao::getOpinionId)
.listAs(Integer.class);
opinionPreWarningVo.setOpinionIdList(ids);
}
return BaseResult.returnSuccessMessageOkAndData(opinionPreWarningVoPage);
}
}
}附其他文件:
Dao
package com.xxx.AnimationOpinionControlSystem.pojo.dao;
import com.fasterxml.jackson.annotation.JsonFormat;
import com.mybatisflex.annotation.Column;
import com.mybatisflex.annotation.Id;
import com.mybatisflex.annotation.KeyType;
import com.mybatisflex.annotation.Table;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.time.LocalDateTime;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
@Table("animation_opinion_5_classified_result")
public class OpinionClassifiedResultDao {
/** 主键自增长,分类结果Pk */
@Id(keyType = KeyType.Auto)
private Integer classifiedResultPk;
/** 主键自增长,分类结果ID */
private String classifiedResultId;
/** 舆情ID */
private Integer opinionId;
/** 默认-1,舆情类型,1-bug类,2-需求类 */
private Integer opinionType;
/** 默认-1,情感类型,1-负向,2-中性,3-正向,4-负向(未明确场景) */
private Integer emotionType;
/** os版本信息 */
private String osVersion;
/** 主分类ID */
private Integer mainCategoryId;
/** 一级分类ID 主键 */
private Integer levelOneCategoryPk;
/** 二级分类ID 主键 */
private Integer levelTwoCategoryPk;
/** 分类备注 */
private String classifiedRemark;
/** 默认1,审核状态,1-初筛,2-复审,3-公开,4-已废弃 */
private Integer reviewStatus;
/** 分类结果创建人工号 */
private String classifiedResultCreatorId;
/** 分类结果更新人工号 */
private String classifiedResultUpdaterId;
/** 默认0, 数据版本,更新数据,自动+1 */
@Column(version = true)
private Integer dataVersion;
/** 创建时间 */
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime createTime;
/** 更新时间 */
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime updateTime;
}Vo
package com.xxx.AnimationOpinionControlSystem.pojo.vo;
import com.mybatisflex.annotation.RelationOneToOne;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class OpinionPreWarningVo {
/** os版本信息 */
private String osVersion;
/** 主分类ID */
private Integer mainCategoryId;
/** 一级分类ID 主键 */
private Integer levelOneCategoryPk;
/** 二级分类ID 主键 */
private Integer levelTwoCategoryPk;
/** 分类结果ID */
private String classifiedResultId;
/** 舆情数量 */
private Long opinionCount;
/** 反馈渠道 */
private Integer feedbackChannel;
/** 预警阈值 */
private Integer opinionThreshold;
/** 舆情原声列表 */
private List<String> originalOpinionLinkList;
/** 舆情ID列表 */
private List<Integer> opinionIdList;
/** 舆情问题ID,格式为AOP241119001,即动效舆情问题缩写AOP+年月日+三位数问题序号 */
@RelationOneToOne(selfField = "classifiedResultId", targetField = "classifiedResultId", targetTable = "animation_opinion_6_problem_binding_detail", valueField = "opinionProblemId")
private String opinionProblemId;
// OpinionMainCategoryDao 属性
/** 主分类描述 */
@RelationOneToOne(selfField = "mainCategoryId", targetField = "mainCategoryId", targetTable = "animation_opinion_2_main_category", valueField = "mainCategoryDescription")
private String mainCategoryDescription;
// OpinionLevelOneCategoryDao 属性
/** 一级分类描述 */
@RelationOneToOne(selfField = "levelOneCategoryPk", targetField = "levelOneCategoryPk", targetTable = "animation_opinion_3_level_one_category", valueField = "levelOneCategoryDescription")
private String levelOneCategoryDescription;
/** 一级分类ID */
@RelationOneToOne(selfField = "levelOneCategoryPk", targetField = "levelOneCategoryPk", targetTable = "animation_opinion_3_level_one_category", valueField = "levelOneCategoryId")
private Integer levelOneCategoryId;
// OpinionLevelTwoCategoryVo 属性
/** 二级分类描述 */
@RelationOneToOne(selfField = "levelTwoCategoryPk", targetField = "levelTwoCategoryPk", targetTable = "animation_opinion_4_level_two_category", valueField = "levelTwoCategoryDescription")
private String levelTwoCategoryDescription;
/** 二级分类ID */
@RelationOneToOne(selfField = "levelTwoCategoryPk", targetField = "levelTwoCategoryPk", targetTable = "animation_opinion_4_level_two_category", valueField = "levelTwoCategoryId")
private Integer levelTwoCategoryId;
}
Dto
package com.xxx.AnimationOpinionControlSystem.pojo.dto.OpionionPreWarning;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class QueryPreWarningInfoDto {
/** 舆情预警类型 */
@NotNull(message = "opinionPreWarningType 不能为null")
private Integer opinionPreWarningType;
/** 反馈开始日期 */
@NotNull(message = "feedbackStartDate 不能为null")
@NotBlank(message = "feedbackStartDate 不能为空字符串")
private String feedbackStartDate;
/** 反馈结束日期 */
@NotNull(message = "feedbackEndDate 不能为null")
@NotBlank(message = "feedbackEndDate 不能为空字符串")
private String feedbackEndDate;
/** 是否查询所有list,1-是,其他情况,否 */
private Integer whetherQueryAllList;
/** 页面索引 */
@NotNull(message = "页面索引 不能为null")
private Integer pageIndex;
/** 页面大小 */
@NotNull(message = "页面大小 不能为null")
private Integer pageSize;
}1.3.3 MybatisPlus
1.4 中间件-消息队列
1.4.1 RocketMQ
1.4.1.1 配置方法
# RocketMQ 配置
rocketmq:
# RocketMQ 地址
name-server: IP:9876
producer:
# 当前生产者(服务)所属的生产者组
group: begs-producer-dev上述配置表示为当前生产者配置一个[生产者组](#1.4.1.4 生产者组(Producer Group))名。
1.4.1.2 监听方法 / 消息消费
@RocketMQMessageListener(topic = "topic-bugUpdateTask", consumerGroup = "consumerGroup-bugUpdateTask", consumeMode = ConsumeMode.ORDERLY)消息的发送是基于 Topic
消费模式
顺序消费(Orderly):
- 消息将按照生产者发送消息的顺序逐一处理。
- 同一消息队列中的消息被 顺序消费,即消息消费的顺序与生产消息的顺序相同。
- 如果消费一个队列的消息时出现问题,RocketMQ 会继续从该队列中消费下一条消息,而不会跳到其他队列。即使消费失败,它会尝试重试当前队列中的消息。
- RocketMQ 会为每个 消息队列 分配一个 消费线程,并确保该线程按照消息的顺序进行消费。
- 如果有多个队列,消息会被分发到不同的消费线程上处理,但每个线程内部的消费是有序的。
- 适合需要确保消息顺序的场景,例如事务处理、订单系统、支付系统等。
并行消费(Concurrently):
- 在并行消费模式下,RocketMQ 会按并行消费的方式将同一个队列中的消息分配给多个消费线程,或者从多个消息队列中并行消费消息,即不保证顺序。
- 不保证同一个消息队列中的消息按顺序消费。
- 该模式适用于对消息顺序没有严格要求的场景,能够提高消息的处理吞吐量。
- 但如果消费队列中的消息有严格的顺序要求,可能会出现问题。
1.4.1.3 消息生产 / 发送
rocketMqTemplate.convertAndSend("topic-catchGlobalException", collectGlobalExceptionEventDto);1.4.1.4 生产者组(Producer Group)
介绍
当启动多个生产者实例时,它们会被归为同一个组,使用这个组名向 RocketMQ 发送消息。
在 RocketMQ 中,生产者组 是 逻辑上的分组。生产者实例(服务)在发送消息时,只需声明属于哪个生产者组,而不需要显式地向生产者组注册自己的 IP 地址或端口。
作用
消息发送统计与管理:RocketMQ 使用生产者组来统计和管理消息的发送状态、发送频率、负载均衡以及进行流控等。虽然消息的发送是基于
Topic,但 RocketMQ 会根据生产者组进行资源调度。故障恢复与重试:在分布式系统中,如果一个生产者实例失败了,另一个生产者实例仍然可以继续通过同一个生产者组进行消息发送。
配置共用:所有的生产者共用一个生产者组配置。这个可以在配置文件里写,也可以写java代码
1.4.1.5 消费者组(Consumer Group)
介绍
消费者组也是逻辑分组,其作用是管理多个消费者实例,并确保消息在消费者组内的 负载均衡消费。
作用
- 消息消费分配与负载均衡:消费者组帮助 RocketMQ 将消息 均匀地分配 给组内的各个消费者实例。
- 消息消费的可靠性:消费者组使得消息消费的可靠性得到保障。如果某个消费者实例失败,会分配给同一个消费者组中的其他消费者实例,确保没有消息丢失。
Topic和Group结合:消费者组监听Topic,并从该Topic中获取并消费消息。如果没有配置消费者组,RocketMQ 会认为所有的消费者都属于一个默认的消费者组,这样每个消息将被所有消费者实例同时消费。- 配置共用
1.4.1.6 消息路由
消息路由是指消息从生产者发送到 RocketMQ 中的 消息队列的过程。它决定了每条消息会被路由到哪个消息队列。
消息队列的选择:每个
topic下有多个queue(使用 MQAdminExt 手动配置)。生产者通过消息路由算法选择将消息发送到哪个消息队列。负载均衡策略:对于多个生产者实例,RocketMQ 会使用一定的策略(如轮询、哈希等)来分配消息队列。生产者会通过这些策略将消息发送到不同的队列,以实现负载均衡。
常见的消息路由方式:
- 轮询方式(Round-robin):如果生产者组中有多个生产者实例,它们会轮流选择消息队列进行消息的发送。每个生产者轮流选择消息队列,确保负载均衡。
- 哈希方式(Hashing):在某些场景下,RocketMQ 会使用哈希算法来将消息发送到特定的队列。通常是通过消息的内容(如
messageKey或messageId)来决定消息路由到哪个队列。例如,同一个messageKey的消息可能会总是被路由到同一个队列,以保证消息的顺序性。 - 广播方式(Broadcast):对于广播消息模式,RocketMQ 会将消息广播到所有的队列,不进行负载均衡。所有的消费者都能够接收到相同的消息。
RabbitMQ
Kafka
1.5 中间件-Redis
Redis 是一个开源的、基于内存的、可可选持久化的 键值对存储数据库。它通常被用作 缓存、数据库、消息代理和实时数据处理引擎。
Config
Spring:
# redis配置
redis:
host: 172.16.101.171
port: 6379
# redis访问密码
password: jzjxRedis
# 连接超时时间 单位毫秒 10秒
timeout: 10000
# 默认数据库 - 第1个数据库,一共有16个DB
database:
db0: 0
db1: 1
db2: 2
jedis:
pool:
# 连接池最大连接数(使用负值表示没有限制) 默认为 8
max-active: 1000
# 连接池最大阻塞等待时间(使用负值表示没有限制) 默认为 -1 ,单位ms
max-wait: -1
# 连接池中的最大空闲连接 默认为 8
max-idle: 10
# 连接池中的最小空闲连接 默认为 0
min-idle: 5package com.xxx.PlatformBuriedPointSystem.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.connection.RedisConfiguration;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.connection.lettuce.LettucePoolingClientConfiguration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
@Configuration
@Slf4j
public class RedisConfig {
@Value("${spring.redis.database.db0}")
private int db0;
@Value("${spring.redis.database.db1}")
private int db1;
@Value("${spring.redis.database.db2}")
private int db2;
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.password}")
private String password;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.timeout}")
private int timeout;
@Value("${spring.redis.jedis.pool.max-active}")
private int maxActive;
@Value("${spring.redis.jedis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.jedis.pool.min-idle}")
private int minIdle;
@Value("${spring.redis.jedis.pool.max-wait}")
private long maxWait;
@Bean
public GenericObjectPoolConfig<Object> getGenericObjectPoolConfig() {
// 配置redis连接池
GenericObjectPoolConfig<Object> poolConfig = new GenericObjectPoolConfig<>();
poolConfig.setMaxTotal(maxActive);
poolConfig.setMaxIdle(maxIdle);
poolConfig.setMinIdle(minIdle);
poolConfig.setMaxWaitMillis(maxWait);
return poolConfig;
}
@Primary
@Bean(name = "redisTemplateDb0")
public RedisTemplate<String, Object> getRedisTemplateOfDb0() {
return getRedisTemplateByLettuceConnectionFactory(db0);
}
@Bean(name = "redisTemplateDb1")
public RedisTemplate<String, Object> getRedisTemplateOfDb1() {
return getRedisTemplateByLettuceConnectionFactory(db1);
}
@Bean(name = "redisTemplateDb2")
public RedisTemplate<String, Object> getRedisTemplateOfDb2() {
return getRedisTemplateByLettuceConnectionFactory(db2);
}
public RedisTemplate<String, Object> getRedisTemplateByLettuceConnectionFactory(int databaseIndexName) {
RedisConfiguration redisConfiguration = new RedisStandaloneConfiguration(host, port);
// 设置选用的数据库号码
((RedisStandaloneConfiguration) redisConfiguration).setDatabase(databaseIndexName);
// 设置 redis 数据库密码
((RedisStandaloneConfiguration) redisConfiguration).setPassword(password);
LettucePoolingClientConfiguration.LettucePoolingClientConfigurationBuilder builder
= LettucePoolingClientConfiguration.builder()
.commandTimeout(Duration.ofMillis(timeout));
LettucePoolingClientConfiguration lettucePoolingClientConfiguration = builder.build();
builder.poolConfig(getGenericObjectPoolConfig());
// 根据配置和客户端配置创建连接
LettuceConnectionFactory factory = new LettuceConnectionFactory(redisConfiguration, lettucePoolingClientConfiguration);
// 一定要执行下一步操作,保存配置,否则会报NPL问题
factory.afterPropertiesSet();
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(factory);
//使用Jackson2JsonRedisSerialize 替换默认序列化(默认采用的是JDK序列化) key采用StringRedisSerializer, value采用Jackson2JsonRedisSerializer
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.WRAPPER_ARRAY);
jackson2JsonRedisSerializer.setObjectMapper(om);
redisTemplate.setKeySerializer(stringRedisSerializer);//key序列化
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); //value序列化
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}实战
package com.xxx.PlatformBuriedPointSystem.consumer;
import com.alibaba.fastjson.JSON;
import com.mysql.cj.util.StringUtils;
import com.xxx.PlatformBuriedPointSystem.common.MyConstants;
import com.xxx.PlatformBuriedPointSystem.exception.MyException;
import com.xxx.PlatformBuriedPointSystem.mapper.BuriedPointEventRecordMapper;
import com.xxx.PlatformBuriedPointSystem.pojo.dao.BuriedPointEventRecordDao;
import com.xxx.PlatformBuriedPointSystem.pojo.dao.MessageQueueConsumptionEventDao;
import com.xxx.PlatformBuriedPointSystem.pojo.dto.BuriedPointEventRecordDto;
import lombok.extern.slf4j.Slf4j;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.spring.annotation.ConsumeMode;
import org.apache.rocketmq.spring.annotation.RocketMQMessageListener;
import org.apache.rocketmq.spring.core.RocketMQListener;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.nio.charset.StandardCharsets;
@Slf4j
@Component
@RocketMQMessageListener(topic = "topic-buriedPointEvent", consumerGroup = "consumerGroup-buriedPointEvent", consumeMode = ConsumeMode.ORDERLY)
public class BuriedPointEventRecordConsumer implements RocketMQListener<MessageExt> {
@Resource
private BuriedPointEventRecordMapper buriedPointEventRecordMapper;
@Resource(name = "redisTemplateDb2")
private RedisTemplate<String, Object> redisTemplate;
@Override
public void onMessage(MessageExt message) {
// 定义为顺序消费模式,保证每条消息,只被消费一次
// 1、确认消息是否被消费过,重复消费次数 为0,表示未被消费
if (message.getReconsumeTimes() > 0) {
return;
}
// 2、数据库通过消息ID,查询是否存在对应的消息,若存在,说明有消费记录
String messageId = message.getMsgId();
Object value = redisTemplate.opsForValue().get(messageId);
if (value != null) {
return;
}
// 3、数据库没有对应记录,则在数据库中插入对应的消息信息,并将消息的消费状态设置为 “consuming”
String messageBody = new String(message.getBody(), StandardCharsets.UTF_8);
// 3.1、如果消息体内容,为空或者null,则为异常情况
if (StringUtils.isNullOrEmpty(messageBody)) {
throw new MyException("message content is null or empty,messageBody = " + messageBody);
}
// 3.2、将消息Body解析为对应的DTO类
BuriedPointEventRecordDto buriedPointEventRecordDto = JSON.parseObject(messageBody, BuriedPointEventRecordDto.class);
// 3.3、消息内容,设置为对应DTO类的JSON 字符串
MessageQueueConsumptionEventDao messageQueueConsumptionEventDao = new MessageQueueConsumptionEventDao();
messageQueueConsumptionEventDao
.setMessageId(messageId)
.setMessageContent(JSON.toJSONString(buriedPointEventRecordDto))
.setMessageConsumptionStatus(MyConstants.MESSAGE_QUEUE_CONSUMPTION_STATUS_CONSUMING)
.setBusinessPlatform("BEGS")
.setBusinessType("vChatMessageSend")
.setTopicName("topic-buriedPointEvent");
redisTemplate.opsForValue().set(messageId, JSON.toJSON(messageQueueConsumptionEventDao));
// 4 处理具体业务
BuriedPointEventRecordDao buriedPointEventRecordDao = new BuriedPointEventRecordDao();
buriedPointEventRecordDao
.setEventId(buriedPointEventRecordDto.getEventId())
.setEventLabel(buriedPointEventRecordDto.getEventLabel())
.setUserUuid(buriedPointEventRecordDto.getUserUuid())
.setUserIp(buriedPointEventRecordDto.getUserIp());
if (buriedPointEventRecordMapper.insert(buriedPointEventRecordDao) != 1) {
throw new MyException("buriedPointEventRecordDao failed to insert");
}
// 5 以上业务若处理成功,则删除对应的消息
redisTemplate.delete(messageId);
}
}Redisson
看门狗
1.6 Spring Cloud/服务/微服务
Spring Cloud 的项目核心目标,就是提供一套完整的微服务架构解决方案。它定义了一套标准的、抽象的客户端接口。
1.6.1 Feign
什么是 Feign?
Feign 是 Netflix 开源的一个声明式 HTTP 客户端库,Spring Cloud 对其进行了二次封装(Spring Cloud OpenFeign)。
它能让你把远程 HTTP 接口 “像本地方法” 一样调用:只需定义一个 Java 接口,添加几个注解,就能完成序列化、反序列化、请求构造、负载均衡、熔断等一系列工作。
- 简洁:不用手写
RestTemplate、HttpClient代码,避免重复造轮子。 - 声明式:接口与注解就能定义 API,代码可读性高。
- 可扩展:支持超时、拦截器、错误解码、调用重试、熔断降级等。
- 与 Spring Cloud 生态集成:自动结合服务发现、负载均衡(Ribbon/LoadBalancer)、熔断(Hystrix/Resilience4j)等。
在项目中引入 Feign
依赖(以 Spring Cloud Alibaba 为例)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> <version>${spring-cloud-starter-openfeign.version}</version> </dependency>启动类上开启 Feign
@SpringBootApplication
@EnableFeignClients // 扫描并注册所有带 @FeignClient 的接口
public class Application { … }定义 Feign 客户端接口
@FeignClient(
name = "file-service-center-api",
url = "${host.file-service-center}",
configuration = FeignConfig.class
)
public interface FileServiceCenterBackEndClient {
@PostMapping(value = "/upload/singleFile", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
BaseResult uploadSingleFile(
@RequestPart("file") MultipartFile file,
@RequestPart("uploadSingleFileDto") UploadSingleFileDto dto);
// … 其他接口方法 …
}直接指定url是不会通过注册中心发送请求的,是直接请求。
对比手动拼装 HTTP 请求优势
代码量:手动拼装 HTTP 请求需显式构造 URL、头部、请求体和异常处理;Feign 只需定义接口和注解,自动完成序列化、反序列化和调用逻辑。
关注点分离:手动方式让业务代码混进大量网络细节;Feign 客户端将网络调用抽象为接口,业务层只聚焦核心逻辑。
统一配置:超时、重试、日志等要在每次调用处或底层工具中单独配置;Feign 只在一个配置类(FeignConfig)里集中管理。
生态集成:手动方式要自己接入并配置 Ribbon、熔断、监控等;Feign 与 Spring Cloud 深度整合,这些能力开箱即用。
可测试性:手动调用需要模拟 HTTP 服务器或 mock RestTemplate;Feign 接口可直接用 @MockBean 或 Mockito 轻松替代。
核心注解属性
| 属性 | 含义 |
|---|---|
| name | FeignClient 的逻辑名称,也同时作为 Spring Bean 名称(默认小写接口名)。 如果不指定 url,就会把它当作注册中心的服务 ID 去发现实例:根据 name 去注册中心找对应的服务,针对服务下的 host 轮询或随机请求。 |
| url | 目标服务的基础 URL。 - 每个方法上的映射路径(如 /upload/singleFile)会拼接到这里。 |
| configuration | 指定仅应用于本 FeignClient 的配置类。 可以集中管理超时、拦截器、编码解码器、错误处理等。 |
统一配置:FeignConfig
@Configuration
public class FeignConfig {
@Bean
public Request.Options options() {
return new Request.Options(10L, TimeUnit.SECONDS, 300L, TimeUnit.SECONDS, true);
}
}使用方法
@Service
public class MyBusinessService {
private final FileServiceCenterBackEndClient fileClient;
public MyBusinessService(FileServiceCenterBackEndClient fileClient) {
this.fileClient = fileClient;
}
public void processAndUpload(MultipartFile file) {
UploadSingleFileDto dto = new UploadSingleFileDto(/* 填充你的参数 */);
BaseResult result = fileClient.uploadSingleFile(file, dto);
if (!result.isSuccess()) {
throw new BusinessException("上传失败:" + result.getMessage());
}
// 继续后续业务
}
}1.6.2 服务间通信 / 远程服务调用
服务发现(Service Discovery)
Http客户端(Feign)通过客户端均衡负载(Ribbon / Spring Cloud LoadBalancer)向注册中心(Eureka/Consul)查询“我想调用的服务名对应哪些健康实例”。
客户端负载均衡(Client‑Side Load Balancing)
拿到实例列表后,按轮询、随机、加权等策略在本地选一台机器。
远程调用(Remote Call)
由 Feign 声明式地构造和发送 HTTP 请求,发送到选中的实例地址,并处理响应。
1.6.3 HTTP 客户端
| 客户端 | 类型 | 声明式支持 | 底层实现 | 优缺点 | 适用场景 |
|---|---|---|---|---|---|
| Feign / OpenFeign | 同步/阻塞 | 原生支持 | 可插拔(默认 OkHttp / Apache HttpClient) | + 接口注解化、集成 Ribbon/Eureka+ 自动序列化/反序列化– 性能受限于底层 HTTP 客户端 | Spring Cloud 微服务间远程调用 |
| RestTemplate | 同步/阻塞 | 无 | HttpURLConnection / Apache HttpClient | + 简单易用– Spring5 后被标为过时,不再增强 | 传统 Spring MVC 项目(简单场景) |
| Apache HttpClient | 同步/阻塞 | 无 | Apache HttpClient | + 功能全面、配置灵活– 框架较重,配置繁琐 | 需要高级连接池、SSL、代理等控制的场景 |
| OkHttp | 同步/阻塞 | 无 | OkHttp | + 性能高、友好连接池+ 支持 HTTP/2、WebSocket– Java 服务端需显式引入 | 高并发服务端、Android 客户端 |
| Java 11+ HttpClient | 同步/阻塞 | 无 | JDK 内置 | + 零额外依赖、API 现代化– 功能基础,某些高级需求需自行扩展 | 简单 HTTP 调用,无需第三方依赖 |
| JAX‑RS Client | 同步/阻塞 | 注解驱动 | Jersey / RESTEasy | + 规范化、可替换实现– 学习和配置成本比 RestTemplate 略高 | Jakarta EE / JAX‑RS 生态 |
| WebClient | 异步/反应式 | 部分支持 | Reactor + Netty | + 反应式、支持流式处理+ 资源利用高– 编程模型复杂度高 | 高并发、流式数据、响应式微服务 |
| AsyncHttpClient | 异步/回调 | 无 | Netty | + 超高吞吐、低延迟– API 回调式,使用复杂 | 极端性能场景 |
| Vert.x WebClient | 异步/回调 | 无 | Vert.x Event Loop | + 轻量、集成 Vert.x 生态– 依赖 Vert.x | Vert.x 应用 |
| Retrofit | 同步/阻塞 + 异步 | 原生支持 | OkHttp | + 注解化、灵活易用+ Android 社区成熟– 服务发现/负载均衡需手动集成 | Android 客户端/轻量 Java 服务端 |
| Reactive Feign | 异步/反应式 | 原生支持 | WebClient | + 声明式 + 反应式– 社区生态较新,文档稍少 | 需要声明式接口同时享受反应式 I/O 的场景 |
1.6.4 服务发现与负载均衡
注意:Nginx 是一个传统的 反向代理服务器,它可以通过 DNS 或配置文件指向多个后端服务实例,进行负载均衡(例如,轮询、IP 哈希、加权等)。但是,它并没有像 Ribbon、Spring Cloud LoadBalancer 等那样与服务注册中心直接集成,不具备服务发现功能。
| 特性 / 方案 | Ribbon + Eureka | Spring Cloud LoadBalancer + Discovery Client | Kubernetes DNS + Envoy 或 Istio | API Gateway(Nginx、Zuul、Spring Cloud Gateway) | gRPC + xDS |
|---|---|---|---|---|---|
| 现状 | Netflix Ribbon 已维护模式,不推荐新项目使用 | 官方推荐,用 Spring Boot Starter 即可接入 | 服务网格(Service Mesh)主流方案,适合大规模集群 | 侧重于“边缘路由+熔断” | gRPC 官方推荐的动态负载均衡接口 |
| 服务发现集成 | Eureka / Consul / ZK(注册中心) | 同上 | Kubernetes API Server(通过 sidecar 自动同步) | 通常和 Eureka、Consul、Kubernetes 集成 | xDS 握手至控制平面(Envoy / Istio 控制面) |
| 依赖组件 | spring-cloud-starter-netflix-ribbon | spring-cloud-starter-loadbalancer + discovery | Istio / Linkerd / Consul Connect | Spring Cloud Gateway、Nginx、Zuul | grpc-java + grpc-xds |
| 负载均衡策略 | 轮询、随机、权重、最少并发 | 同 Ribbon,可自定义 | 在 Envoy sidecar 里配置,支持更丰富的 LB 策略(重试、熔断、镜像) | 主要做路由匹配、限流、熔断,LB 能力弱 | 支持轮询、最少连接、权重等,由 Envoy 或 gRPC 客户端实现 |
| 推荐客户端 | - RestTemplate + @LoadBalanced- Feign + Ribbon |
- Feign + Spring Cloud LoadBalancer- WebClient + Spring Cloud LoadBalancer | - 原生 HTTP 客户端(OkHttp / JDK HttpClient / WebClient)- gRPC-Web via Envoy | - 任意 HTTP 客户端(RestTemplate / WebClient / OkHttp)- gRPC 客户端(若网关支持) | - gRPC Java Client + xDS- Envoy gRPC-Web + HTTP 客户端 |
| 流量控制 & 可观测性 | 基础 | 基础 | 丰富:mTLS、Tracing、Metrics、流量镜像、金丝雀发布 | 基础到中等;Gateway 支持限流、熔断 | Envoy 提供,可结合 Service Mesh |
| 运维复杂度 | 低 | 低 | 高:需要额外组件(Istio)、学习成本和运维成本较高 | 中:部署和维护 Gateway | 中:需部署 xDS 控制面和 Envoy sidecar |
| 适用场景 | 小规模微服务,快速上手 | 推荐所有 Spring Cloud 项目 | 大规模集群、零信任安全、高级流量管理需求 | 边缘网关、路由聚合 | 高性能 RPC、双向流、跨语言服务发现 |
1.6.5 注册中心
在微服务架构中,注册中心(Service Registry/Discovery Server)是负责管理和提供“服务名称 ↔ 实例地址”映射关系的关键组件。
它的核心使命是让“调用方”能够动态地找到“被调用方”——而无需硬编码 IP 或端口。
注册中心本质上是分布式内存数据结构,为秒级心跳和查询提供高性能
注意,一些服务发现和负载均衡方式无需单独使用注册中心,如选用 gRPC + xDS,就把注册/发现功能交给 xDS 控制平面,不再需要像 Eureka/Nacos 那样单独部署注册中心。
| 注册中心 | 类型 | 存储机制 | 健康检查 | 数据一致性 | 配置管理 | 生态集成 | 典型使用场景 |
|---|---|---|---|---|---|---|---|
| Nacos | 一体化平台 | 内存 + 持久化 | 心跳 + 可自定义探活 | 最终一致 | ✅(灰度、命名空间) | Spring Cloud Alibaba、Dubbo | 国内微服务 + 动态配置 |
| Eureka | 服务发现 | 内存 + 自我保护 | 心跳 | 最终一致 | ❌ | Spring Cloud Netflix | 中小规模 Spring Cloud |
| Consul | KV + 服务发现 | Raft 分布式存储 | HTTP/TTL、TCP 探活 | 强一致(Raft) | ✅(KV 存储) | 多语言、DNS、Envoy、Nomad | 弹性伸缩、跨语言微服务 |
| ZooKeeper | 通用协调 | Zab 协议 | 临时节点 + Watch | 强一致(Zab) | ❌ | Kafka、HBase、Dubbo | 需要严格一致性的元数据管理 |
| etcd | 分布式 KV | Raft 协议 | TTL 租约 | 强一致(Raft) | ✅(简单 KV) | Kubernetes、CoreDNS | Kubernetes 控制面、云原生架构 |
| Kubernetes DNS | 内置服务注册 | API Server → CoreDNS | Pod/Service 状态 | 强一致(etcd) | ❌ | Kubernetes 原生 | 容器化集群下的“零配置”服务发现 |
| AWS Cloud Map | 托管服务 | AWS Route 53 DNS | AWS Health Check | 最终一致 | ✅(Parameter Store) | ECS/EKS、Lambda | AWS 原生托管微服务 |
| Azure Service Fabric | 平台内置 | Reliable Collections | Fabric Health | 强一致 | ✅(Config API) | Service Fabric 环境 | Azure Service Fabric 集群 |
| gRPC + xDS | RPC 控制面 | 控制平面 + Envoy | Envoy 健康检查 | 最终一致/强一致 | ❌ | Istio、Envoy | 高性能双向流、跨语言 RPC 场景 |
nacos
Nacos(全称 Dynamic Naming and Configuration Service)是阿里巴巴开源的一个一站式服务发现、配置管理和服务治理平台,主要用于微服务架构下的服务发现与管理。Nacos 提供了服务注册、配置管理、动态 DNS 和健康检查等功能,帮助开发者实现微服务的灵活管理和高可用性。
核心功能
- 服务发现与注册
- 微服务在启动时,自动向 Nacos 注册其服务信息(如服务名、IP、端口、元数据等)。
- 服务调用方可以通过 Nacos 查找并获取服务的实例列表,支持自动负载均衡。
- 支持主动的健康检查,当某个服务实例不可用时,Nacos 会及时从注册列表中移除,避免发送请求到不可用的服务。
- 动态配置管理
- Nacos 可以集中管理应用的配置信息(如数据库连接信息、API 密钥、业务参数等)。
- 提供 灰度发布、版本控制、多环境支持,可以方便地进行配置更新,且支持 热更新(无需重启应用)。
- 支持 命名空间、分组、配置多层级管理。
- 服务健康监测
- Nacos 会定期对注册的服务实例进行健康检查,确保服务在失效时能及时剔除并通知消费者。
- 健康检查支持基于 HTTP、TCP、DNS 等协议,可以非常灵活地设置。
- 动态 DNS 服务
- 提供基于服务名的 DNS 解析,可以通过标准的 DNS 协议来访问服务实例,实现服务的快速发现和动态调整。
- 支持多种协议
- 支持通过 HTTP、gRPC、Dubbo 等协议进行服务通信,并为这些协议提供良好的集成支持。
- 支持 Kubernetes 集群
- Nacos 可以与 Kubernetes 集成,自动注册 Kubernetes Pod 为服务实例,实现服务的自动发现和管理。
spring:
# 数据库
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://IP:3306/fluency?useSSL=false&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxxx
password: xxxx
# nacos 注册名称
application:
name: Dev-begs-07-case-collection-system
cloud:
nacos:
discovery:
# Nacos 注册中心的地址
server-addr: IP:8848
group: DEFAULT_GROUP配置了 spring.application.name 和 server-addr 后,Spring Boot 应用会自动把自己注册到 Nacos 的 服务注册中心。
配置之后,Feign只写name不写url会自动从Nacos里发现服务。
1.6.6 网关
所有外部请求进入微服务系统的唯一入口,负责对请求进行统一的管理、检查和路由。
统一入口 (Single Entry Point)
功能:所有客户端(App、浏览器)只与网关交互,不知道也不需要知道内部有哪些微服务以及它们的地址。
好处:解耦客户端与后端服务。后端服务可以随时拆分、合并、升级、迁移,只要网关的路由规则相应改变,客户端无需任何修改。
身份认证与授权 (Authentication & Authorization)
功能:在网关层统一验证用户身份(登录态Token是否有效)、检查用户是否有权限访问目标资源。
好处:避免每个微服务都重复实现一套鉴权逻辑,保证安全策略的一致性。非法请求在进入内部网络前就被拦截。
路由转发 (Routing)
功能:根据请求的路径(如
/api/users/**)、方法(GET/POST)等,将请求转发到对应的后端微服务实例。好处:网关集成服务发现功能(如Nacos、Eureka),能自动找到健康的服务实例,并实现负载均衡。
流量控制与熔断 (Rate Limiting & Circuit Breaker)
功能:
限流:限制每个用户/IP在一段时间内的请求次数,防止恶意攻击或流量洪峰冲垮系统。
熔断:当某个后端服务响应慢或大量失败时,网关可以暂时停止向其转发请求(熔断),直接返回一个预设的降级响应,避免故障扩散。
好处:保护后端服务,提升系统整体的弹性和可用性。
日志记录与监控 (Logging & Monitoring)
功能:作为所有流量的必经之地,网关可以统一收集请求和响应日志、监控API性能(耗时、QPS、错误率等)。
好处:为排查问题、分析数据和系统优化提供 centralized 的数据支持。
其他常用功能
请求/响应转换:对请求进行修改、校验、包装,或对响应进行过滤、聚合。
SSL 终端:在网关处理HTTPS加密/解密,减轻后端服务的压力。
缓存:缓存一些频繁请求的静态数据或结果。
服务拆分
1.7 Spring / Springboot
Spring是一个强大的Java开发框架,提供了一系列的应用模块支持需求,包括依赖注入、面向切片编程、事务管理、web应用程序开发等。
Springboot简化了Spring应用程序的开发和部署,相当于全自动洗衣机,特别是用于微服务和快速开发的应用程序。
Springboot的优势:
自动配置
Spring Boot 通过Auto-Configuration来减少开发人员的配置工作。我们可以通过一个starter就把依赖导入,启动时会根据项目中引入的 Jar 包,自动为项目配置所需的 Bean。从而告别繁琐配置:无需手动写 @Configuration或 XML 来配置 DataSource、TransactionManager、MVC 等组件。
内嵌Web服务器
Spring Boot内置了常见的Web服务器(如Tomcat、Jetty),这意味着您可以轻松创建可运行的独立应用程序,而无需外部Web服务器。
约定大于配置
SpringBoot中有很多约定大于配置的思想的体现,通过一种约定的方式,来降低开发人员的配置工作。如他默认读取spring.factories来加载Starter、读取application.properties或application.yml文件来进行属性配置等
1.7.1 日志
1.7.1.1 Logback
logback 是 Spring Boot 自带的默认日志框架,允许你快速自定义日志输出行为,尤其是日志的文件存储、滚动策略等。
配置如下:
# 日志配置
logging:
file:
# 日志文件的保存路径
name: F:/0_GerritProject/1_NewServerFluencySystem/000_logFile/07_CaseCollectionSystem_BackEnd/CaseCollectionSystem_${server.port}.log
# 滚动策略配置
logback:
rollingpolicy:
# 应用启动时,清除历史日志
clean-history-on-start: true
# 日志历史保存的最大天数
max-history: 14
max-file-size: 500MB**name**:日志文件的保存路径。
1.7.1.2 与nohup对比
nohup 输出:
- 主要捕获应用程序的 控制台输出,捕获标准输出和标准错误输出(println)。
- 输出内容较为基础,主要包括启动信息、异常堆栈、调试信息等。
- 没有自定义日志格式或结构化输出。
Spring Boot 日志:
- 包含应用的详细日志信息,如业务日志、请求日志、异常堆栈、日志级别(
INFO、DEBUG、ERROR)等。 - 使用 Logback 等日志框架,支持更丰富的日志格式、日志滚动策略、历史日志管理等。
1.7.2 AOP
1.7.2.1 AOP 封装回滚
@Transactional(rollbackFor = Exception.class)1.7.3 事务
[受检异常](#1.11.2 Exception(受检异常)-Java异常)默认不会回滚,需要加 rollbackFor = Exception.class
@Transactional // 不写 rollbackFor:只回滚 RuntimeException
public void foo() throws IOException {
dao.insertA();
if (true) throw new IOException(); // 受检异常 -> 默认不回滚(会提交!)
}
@Transactional(rollbackFor = Exception.class)
public void bar() throws IOException {
dao.insertA();
if (true) throw new IOException(); // 受检异常 -> 回滚
}1.7.4 监控
Spring Boot Actuator
Spring Boot Actuator 是 Spring 官方提供的 应用监控与管理模块。
它会自动暴露一批 REST 风格的监控端点(默认在 /actuator 下),让你能实时查看和管理应用的运行状态。
常见端点:
/actuator/health—— 健康检查(UP/DOWN),常被 K8s、监控系统探活用。/actuator/metrics—— 各种指标(JVM 内存、线程、HTTP 请求数、GC 次数等)。/actuator/env—— 环境属性(系统变量、配置文件里的值)。/actuator/beans—— Spring 容器里的 Bean 列表。/actuator/mappings—— 所有请求映射(controller 的 URL → 方法)。/actuator/loggers—— 动态查看/修改日志级别。
👉 它是开发运维常用的 应用可观测性工具。
如何引入
在 pom.xml 里加:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>1.8 分布式开发
1.8.1 分布式定时任务
1.8.1.1 单机定时任务
@Scheduled(cron = "0 0/5 * * * ?")
public void report() {
System.out.println("每5分钟执行一次任务");
}如果只部署在一台服务器 上,它就能正常执行。但是如果部署了多台机器(微服务集群),这个任务会在每台机器上都跑一遍,这样就会重复执行,数据错乱。
1.8.1.2 分布式定时任务
目标:多台机器同时部署时,保证一个任务只执行一次(或按分片规则分配执行)。
主要有两种模式:
1.8.1.2.1 单点调度
- 只有 一个调度中心(比如 XXL-JOB 的 Admin)。
- 调度中心负责根据 cron 触发任务,并决定派发给哪台执行器。
- 这样就不会出现 “多台机器重复执行” 的问题。
1.8.1.2.2 分片执行
- 有些任务很大,比如要处理 100 万条数据。
- 可以把任务分成 N 份,分给集群里的不同机器并行跑,加快速度。
- 比如 10 台机器,每台机器只处理 1/10 的数据。
1.8.1.3 Xxl-Job
Admin(调度中心)
- 提供一个 控制台网站(本质是一个 Spring Boot 项目)。
- 你在里面配置任务:什么时候跑、在哪些机器跑、失败了怎么重试、保留多少天日志…
- 作用像“管理者”:下达指令,并收集执行结果、日志。
Executor(执行器)
- 就是你们自己的 业务服务(Spring Boot 项目里引入
xxl-job-core),在里面写任务方法。 - 执行器会注册到 Admin,告诉 Admin:“我在这里,有 CPU 可以跑任务”。
- 当时间到时,Admin 触发调度,执行器就去跑任务。
- 执行完毕后,执行器会回调 Admin,告诉它“任务完成/失败了”。
分布式调度(高可用性)
调度中心本身可以部署多个实例,前面挂一个负载均衡(Nginx)。
同一时刻只有一个 Admin 节点触发任务,因为调度中心依赖数据库的分布式锁保证“只有一个节点触发”。
即使一个节点宕机也不影响其他节点继续触发任务,存活的 Admin 会继续抢到锁并触发。
分布式执行(并行加速)
当调度中心触发任务时,Admin 会并行通知 5 个执行器实例,每个实例只处理自己的一部分数据。这样原先2小时的工作可能5分钟内完成。
实例 1 → 处理用户 ID 0~199999
实例 2 → 处理用户 ID 200000~399999
…
实战
在 MySQL / PostgreSQL 里先手动建一个数据库(比如叫 xxl_job),执行 XXL-JOB 提供的建表脚本(/xxl-job/doc/db/tables_xxl_job.sql)来创建表结构。
方法一(docker拉取调度中心)
docker pull xuxueli/xxl-job-admin:3.1.1
/**
* 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;
* 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties
* 如需自定义 JVM内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
*/
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}方法二(拉取源码,自行部署调度中心)
spring:
application:
name: xxl-job-admin
mvc:
servlet:
load-on-startup: 0
static-path-pattern: /static/**
web:
resources:
static-locations: classpath:/static/
freemarker:
template-loader-path: classpath:/templates/
suffix: .ftl
charset: UTF-8
request-context-attribute: request
settings:
number_format: 0.##########
# 配置数据源
datasource:
url: jdbc:mysql://IP:3306/xxl_job?useSSL=false&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: xxxuser
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 10
maximum-pool-size: 30
auto-commit: true
idle-timeout: 30000
pool-name: HikariCP
max-lifetime: 900000
connection-timeout: 10000
connection-test-query: SELECT 1
validation-timeout: 1000
# 报警邮箱
# 任务失败告警:当某个任务在执行过程中报错、超时或多次重试仍失败时,XXL-JOB 会根据任务配置,把失败信息发送到预设的邮箱。
# 调度异常告警:如果执行器机器掉线、注册失败或者触发调度线程池出错,也可以触发告警邮件。
# 报警内容:任务名称 / JobHandler;执行时间、失败次数;错误堆栈或日志片段;对应执行器实例信息
mail:
host: smtp.qq.com
port: 25
from: xxx@qq.com
username: xxx@qq.com
password: xxx
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
xxl:
job:
# 调度中心通讯TOKEN [选填]
accessToken: default_token
# 执行器与调度中心之间 HTTP 通讯的超时时间[选填],默认3s;
timeout: 3
# 调度中心国际化配置 [必填]
i18n: zh_CN
# 调度线程池最大线程配置,限制 Admin 调度中心最多能同时并发触发多少个任务【必填】
triggerpool:
# 快速任务触发(如果耗时 < 500ms → 判定为 fast 任务,以后再触发就丢进 fast 线程池)
fast:
max: 200
slow:
max: 200
# 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
logretentiondays: 30admin节点分布式部署
多 Admin 实例:2~3 个即可。
同一数据库:所有 Admin 指向同一 MySQL(用官方 xxl_job.sql 初始化)。
统一 accessToken:所有 Admin/Executor 的 accessToken 要一致。
负载均衡:使用 Nginx / SLB / K8s Service 做均衡负载,暴露 Nginx(或云 SLB)对外的端口号。
会话问题:控制台登录会话要么开负载均衡粘性会话,要么接 Spring Session + Redis 共享会话。
执行器指向多 Admin:xxl.job.admin.addresses 写成LB(Load Balancer) 地址或多个地址逗号分隔。
Elastic-Job
1.9 Java
1.9.1 Java 中的数据定义
在 Java 里,从底层来看,可以分成两类:
1.9.1.1 基本类型 (Primitive Types)
- 一共 8 种:
byte, short, int, long, float, double, char, boolean。 - 直接存放在 栈(stack frame 的局部变量表)或者 数组的连续内存块里。
- 不存在“引用”,值就是本身。
int[]数组里存放的就是裸的 32 位整型值。
int a = 10; // a 直接存放值 10
int[] arr = {1,2}; // arr 是对象引用,但 arr[0] 存放的是裸的 32 位 int1.9.1.2 引用类型 (Reference Types)
- 包括:所有类(
String、Integer、ArrayList等)、接口、数组本身(int[]、String[]等,数组本身是对象)、泛型类型:如List<String>本身就是一个引用类型。 - 在变量里存放的是一个 引用(指针),指向堆 (heap) 上的对象实例。
- 比如:
ArrayList<Integer>对象里存放的其实是一个Integer[]数组,而Integer又是对象,最终还是存引用。
String s = "hello"; // s 是引用,指向堆中 String 对象
Integer n = 10; // 自动装箱,n 是引用,指向堆中 Integer 对象
String[] arr = new String[5]; // arr 是引用,arr[i] 存放引用(默认 null)1.9.1.2.1 接口 (Interface Types)
定义:接口是一种特殊的引用类型,定义了一组方法规范,但不提供实现。
存储方式:接口变量本质上还是一个 对象引用,指向某个实现了该接口的类的实例。
特点:
不能直接 new 一个接口。
常用于 面向接口编程,解耦实现与调用。
例子:
如下所示,类型在初始化的时候决定,不在左侧写死。
泛型类型参数 <T> 里的 T 必须是引用类型,不可以是基本类型
// list 是 List 接口类型的引用,右边的对象是 ArrayList 实例
List<Integer> list = new ArrayList<>();
List<int[]> list = new ArrayList<>();
list.add(new int[]{1,2,3});
list.add(new int[]{4,5});
// 取出一个元素
int[] arr = list.get(0);
System.out.println(arr[0]); // 输出 1
1.9.1.2.2 泛型 (Generics)
泛型是 Java 提供的一种 类型参数化机制。
传统的类/方法里,类型是写死的;泛型允许你把 类型当作参数 传进去。
换句话说:泛型就是让类型像方法里的变量一样可以被传入。
class Box<T> { // 这里的 Box 就是一个泛型类,T 是类型参数
private T value;
public void set(T value) { this.value = value; }
public T get() { return value; }
}Box<T> → 泛型类型(未具体化的形式)
Box<String> → 泛型类型的一个 实例化形式(concrete parameterization)
T 就是 类型参数,调用时要替换成某个具体的引用类型。
// Java 7 之前必须写全
List<String> list = new ArrayList<String>();
// Java 7+ 支持菱形语法 <>
// ()是该类的构造函数调用
List<String> list = new ArrayList<>();1.9.2 JVM
1.9.3 线程
13分支,多线程编程
1.9.3.1 什么是线程安全
以原生数组为例,它并不是线程安全的。
Java 数组(int[]、Object[] 等)底层就是一块连续内存,JVM 并不会对它的读写加锁。
如果多个线程同时访问数组 只读 → 是安全的(因为不会修改数据)。
如果有线程在 写数组,而其他线程也在读/写 → 就会产生数据竞争,可能读到脏数据、覆盖写入等。
1.9.3.2 如何保证线程安全
1.9.3.2.1 互斥/加锁
通过一种协议,保证在同一时刻,只有一个线程可以访问某个共享资源或代码段(称为临界区)
synchronized关键字 (Java): 可用于修饰方法或代码块。JVM 负责底层的锁的获取和释放,是一种监视器锁。
public class Counter {
private int count = 0;
// 同步方法(锁是当前实例对象 this)
public synchronized void increment() {
count++; // 这个操作现在是原子的
}
// 同步代码块(可以指定不同的锁对象,更灵活)
public void decrement() {
synchronized (this) {
count--;
}
}
}ReentrantLock (Java): 一个显式的锁实现,提供了比 synchronized更灵活的功能,如可重入性、可中断的锁等待、公平锁、尝试获取锁等。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock(); // 手动获取锁
try {
count++;
} finally {
lock.unlock(); // 必须在finally块中确保释放锁
}
}
}1.9.3.2.2 并发安全的数据结构
这些数据结构在内部已经实现了所有必要的同步机制(通常使用了非常精细的锁策略或无锁技术),使得它们的每个公共方法调用都是原子的。开发者无需再额外加锁。
它们通过内部复杂的实现(如分段锁、CAS)来保证多线程环境下数据的一致性和可见性。
具体实现 (Java java.util.concurrent包):
- **
ConcurrentHashMap**: 代替HashMap和Hashtable。它使用分段锁(Java 7)或 CAS +synchronized(Java 8+),实现了极高的并发访问性能。 CopyOnWriteArrayList/CopyOnWriteArraySet**: 采用“写时复制”策略。每次修改(写)操作都会创建底层数组的一个新副本。读操作完全无锁,性能极高。适用于读多写少**的场景。- **
ConcurrentLinkedQueue**: 一个高效的无界非阻塞线程安全队列,使用 CAS 操作实现。 BlockingQueue接口 (ArrayBlockingQueue,LinkedBlockingQueue): 提供了“阻塞”的插入和取出操作,是实现生产者-消费者模型的利器。
优点: 使用简单,性能通常比自己写的粗粒度锁要好得多。
缺点: 需要注意它们的特定语义(如 CopyOnWriteArrayList的最终一致性),且多个方法的组合调用不是原子的(例如,先 concurrentMap.contains(key)再 concurrentMap.put(key, value)需要额外同步)。
1.9.3.2.3 原子变量 / CAS 操作
这是实现无锁并发算法的底层基础,是很多并发安全数据结构的构建基石。
核心思想: 比较并交换。这是一种硬件级别的原子操作(通常由 CPU 指令支持)。它的行为是:“如果变量 V 的值等于预期值 A,那么就将其原子性地更新为新值 B,否则什么都不做并返回当前值”。
如何具体保证安全: 它避免了昂贵的锁开销,通过乐观锁的策略。它假设竞争不激烈,先尝试更新,如果发现值已经被其他线程修改过(与预期值 A 不符),则失败重试。这个循环重试的过程通常称为 自旋。
具体实现 (Java
java.util.concurrent.atomic包):AtomicInteger,AtomicLong,AtomicBooleanAtomicReference<T>AtomicStampedReference<T>: 解决了 CAS 的 ABA 问题(一个值从 A 变成 B 又变回 A,CAS 会误以为它没变过)。import java.util.concurrent.atomic.AtomicInteger; public class Counter { // 使用原子变量,无需锁 private AtomicInteger count = new AtomicInteger(0); public void increment() { // 内部基于 CAS 实现 count.incrementAndGet(); } // 一个复杂的 CAS 示例:只有当前值是 10 时才将其设置为 0 public void resetIfTen() { int oldValue; do { oldValue = count.get(); // 获取当前值 } while (oldValue == 10 && !count.compareAndSet(oldValue, 0)); // 如果当前值不是10,或者CAS设置成功,则退出循环 } }
优点: 性能极高(在低竞争环境下),避免了死锁。
缺点: 在高竞争环境下,自旋会严重消耗 CPU。实现复杂的逻辑(涉及多个变量)非常困难,通常需要求助于锁。
1.9.3.2.4 不可变性(Immutable)
一个对象在构造完成后,其状态就永远无法被修改。如果需要一个新状态,就创建一个全新的对象。
如何具体实现不可变类 (以 Java 为例):
- **将类声明为
final**,防止子类破坏不可变性。 - **将所有字段声明为
private final**。 - 不提供任何可以修改对象状态的方法(即
setter方法)。 - 通过构造器初始化所有字段。如果字段是可变对象的引用,需要进行防御性拷贝。
1.9.4 JPA
JPA(Java Persistence API)是Sun官方(现Oracle)提出的Java持久化规范。它本身是一个标准、一套接口,而不是具体的实现。
可以从ORM、@注解、
ORM(对象关系映射)
Hibernate 是 JPA 的一个主要实现,是“全ORM”框架。而 MyBatis 被认为是一个“半ORM”或“SQL映射”框架,xml最终会映射成sql语句。半ORM框架在对象关系映射(ORM)过程中保留了开发者对 SQL 的完全控制权。而全自动ORM可能要查好几次数据库,不如直接一句SQL查询到位。
将数据库中的表(Table)映射为Java中的实体类(Entity Class)。
将表中的字段(Column)映射为实体类的属性(Field)。
将表中的记录(Row)映射为实体类的对象(Instance)。
通过操作对象,最终由JPA实现框架生成SQL语句并执行,开发者无需编写繁琐的JDBC代码。
元数据注解(Metadata Annotations)
JPA通过注解来配置映射关系,极大简化了配置。这是它比早期Hibernate的XML配置更受欢迎的原因。
常用注解
@Entity: 标明这是一个需要与数据库映射的实体类。
@Table: 指定映射的表名。
@Id: 标明主键字段。
@GeneratedValue: 指定主键生成策略(如自增、UUID等)。
@Column: 指定映射的列名和约束。
@ManyToOne, @OneToMany, @ManyToMany, @OneToOne: 定义表之间的关联关系。
EntityManager:核心接口
这是JPA操作实体的核心接口,相当于Hibernate中的Session或JDBC中的Connection。
它的生命周期由EntityManagerFactory创建和管理。
主要功能:
CRUD操作: persist(entity)(新增), find(class, id)(查询), merge(entity)(更新), remove(entity)(删除)。查询: 创建Query对象执行JPQL。事务管理: 相关操作通常在事务(@Transactional)内进行。缓存管理: 维护一级缓存(Persistence Context),保证在同一上下文中的对象唯一性。
// JPA标准接口 (由Hibernate实现)
EntityManager em = entityManagerFactory.createEntityManager();
// 插入对象 → 自动生成INSERT
em.persist(user);
// 查询对象 → 自动生成SELECT
User u = em.find(User.class, 1L);
// 更新对象 → 自动生成UPDATE
u.setName("Bob");
em.merge(u);
// 删除对象 → 自动生成DELETE
em.remove(u);JPQL(Java Persistence Query Language)
这是一种面向对象的查询语言,语法类似于SQL,但操作的是实体对象和属性,而不是数据库的表和字段。例子: SELECT u FROM User u WHERE u.name = :name优势: 数据库无关性,更符合面向对象的思维。JPA实现会将其翻译成特定数据库的SQL。
持久化上下文(Persistence Context)与缓存
一级缓存: 即EntityManager内部的缓存。在一个事务内,对同一实体对象的多次操作会被缓存和优化,最终可能只生成一条UPDATE SQL,这被称为“脏检查”(Dirty Checking)。二级缓存: 应用级别的缓存,属于EntityManagerFactory,可以被多个EntityManager共享。需要额外的配置和缓存提供商(如Ehcache)。
1.9.5 JDBC
JDBC 是 Java Database Connectivity 的缩写,意为 Java 数据库连接。它是一套标准的 Java API,用于连接和执行 SQL 语句的关系型数据库(如 MySQL, Oracle, PostgreSQL, SQL Server 等)。它是 Java 领域最直接、最底层、最根本的数据库操作方式。
// 1. 建立连接(假设驱动已自动注册)
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "user", "password");
// 2. 直接编写并执行 SQL 语句
Statement stmt = conn.createStatement();
String sql = "INSERT INTO users (name, email) VALUES ('John Doe', 'john@example.com')";
int rowsAffected = stmt.executeUpdate(sql); // 直接返回影响的行数
System.out.println(rowsAffected + " row(s) inserted.");
// 3. 关闭资源
stmt.close();
conn.close();1.9.6 并发
1.9.7 java高级特性和类库
1.9.8 java网络与服务器编程
1.9.9 Java字符串判空
| 方法 | 来源 | null | "" (空串) |
" " (空格串) |
\t\n |
说明 |
|---|---|---|---|---|---|---|
String.isEmpty() |
JDK java.lang.String |
NullPointerException |
T | F | F | 完全等同于string.length()==0 |
StringUtils.isBlank() |
org.apache.commons.lang3.StringUtils |
T | T | T | T | 判定 null/空/空白 都视为“空” |
Strings.isNullOrEmpty() |
Guava com.google.common.base.Strings |
T | T | F | F | isNullOrEmpty 只判 null 或 "",不把空白当空 |
StringUtils.hasText() |
Spring Framework StringUtils |
F | F | F | F | 判定是否至少含一个非空白字符 |
StringUtils.hasLength() |
Spring Framework StringUtils |
F | F | T | T | 只判 str != null && str.length() > 0 |
StringUtils.isNullOrEmpty() |
Spring Framework StringUtils |
T | T | F | F | |
StringUtils.isNullOrEmpty() |
com.mysql.cj.util.StringUtils |
T | T | F | F | 首选,String.isEmpty()基础上加入null判断 |
StringUtils.isEmptyOrWhitespaceOnly() |
com.mysql.cj.util.StringUtils |
T | T | T | T | |
StringUtils.isEmptyOrWhitespaceOnly() |
org.apache.commons.lang3.StringUtils |
T | T | T | T |
1.9.10 Java流操作
map里期待一个函数,将list所有的元素执行一次这个函数重新存放到流中,后续可以用anyMatch进行匹配
List<Integer> numbers = Arrays.asList(1, 2, 3);
// 过滤出大于 1 的数字,然后乘以 10,最后收集成新的 List
List<Integer> result = numbers.stream()
.filter(n -> n > 1) // 只保留 2、3
.map(n -> n * 10) // 变成 20、30
.collect(Collectors.toList());1.9.11 Java传参
java调用某个方法时,如果传递的参数是对象类型,是可以改变外部传入对象的值的,包括对象类型的list。
1.9.12 Java静态函数
静态函数无需创建类实例就能用类名直接调用,但是不可以访问类下的其他变量,包括静态变量
1.9.13 log代码运行时间
获取System.currentTimeMillis()时间,通过log方式读取
1.10 文件传递方法
1.10.1 Base64 编码
什么是 Base64?
Base64 是一种将二进制数据转换为 ASCII 字符串格式的编码方式。它通过将每 3 个字节的二进制数据转换为 4 个 ASCII 字符,便于在文本格式中传输。
适用场景
- 嵌入到 HTML/CSS 中:
- Base64 编码非常适合将小图像(如图标)直接嵌入 HTML 或 CSS 中。这可以减少 HTTP 请求的数量,从而提高页面加载速度。
- JSON/XML 数据传输:
- 在使用 JSON 或 XML 进行数据传输时,Base64 编码可以方便地将图像数据嵌入到文本数据中,避免了对二进制数据处理的复杂性。
- 跨平台兼容性:
- Base64 是文本格式,能够在不同的系统和编程语言间顺利传输,避免了二进制数据在某些情况下的兼容性问题。
优缺点
- 优点:
- 简化数据传输,避免二进制处理复杂性。
- 便于直接嵌入网页,减少 HTTP 请求。
- 缺点:
- 数据量增加约 33%,影响性能。
- 不适合处理大文件。
1.10.2 字节流
什么是字节流?
字节流是一种以二进制格式直接传输数据的方式,适用于文件的上传和下载。
适用场景
- 文件上传与下载:
- 对于大图像文件,使用字节流可以更高效地进行传输,避免了 Base64 编码带来的额外开销。
- 存储和处理大文件:
- 在数据库或文件系统中存储图像时,字节流提供更高的性能,节省带宽和存储空间。
- 支持多种文件类型:
- 除了图像,字节流也能处理多种类型的二进制文件,使其更具灵活性。
优缺点
- 优点:
- 高效处理大文件,避免性能损失。
- 适合多种二进制文件类型。
- 缺点:
- 需要处理二进制数据的复杂性。
- 不适合嵌入文本数据中。
1.10.3 URL 静态资源映射
将图像上传到服务器后,通过 URL 引用图像。这种方式可以大幅减小网页负担,提高加载速度,适合大多数场景。
1.10.4 MinIO
MinIO本质是一种对象存储
1.10.4.1 实战
1.10.4.1.1 Docker拉取
docker run -d -p 9000:9000 -p 9090:9090 \
--name minio \
-e "MINIO_ROOT_USER=admin" \
-e "MINIO_ROOT_PASSWORD=admin123" \
-v /data/minio/data:/data \
-v /data/minio/config:/root/.minio \
quay.io/minio/minio server /data --console-address ":9090"1.10.4.1.2 配置文件
# MinIO 配置
minio:
# minio配置的地址,端口9000
endpoint: http://IP:9000/
# 账号
accessKey: minio-test-user
# 密码
secretKey: test123456
# 按业务模块给不同模块分配桶名
bucketName:
fluency: local-test-bucket
caseSystem: local-test-bucket
animationOpinionControlSystem: local-test-animation-opinion-control-bucket
freeTestSystem: local-test-free-test-bucket1.10.4.1.3 Config
package com.xxx.FileServiceCenter.minIO;
import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@Data
public class MinIoConfig {
@Value("${minio.endpoint}")
private String endpoint;
@Value("${minio.accessKey}")
private String accessKey;
@Value("${minio.secretKey}")
private String secretKey;
@Bean
public MinIoUtils creatMinioClient() {
return new MinIoUtils(endpoint, accessKey, secretKey);
}
}1.10.4.1.4 Utils
package com.xxx.FileServiceCenter.minIO;
import io.minio.*;
import io.minio.http.Method;
import io.minio.messages.Bucket;
import io.minio.messages.DeleteObject;
import io.minio.messages.Item;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.util.FastByteArrayOutputStream;
import org.springframework.web.multipart.MultipartFile;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Optional;
@Slf4j
@Component
public class MinIoUtils {
private static MinioClient minioClient;
private static String endpoint;
private static String accessKey;
private static String secretKey;
private static final String SEPARATOR = "/";
public MinIoUtils() {
}
public MinIoUtils(String endpoint, String accessKey, String secretKey) {
MinIoUtils.endpoint = endpoint;
MinIoUtils.accessKey = accessKey;
MinIoUtils.secretKey = secretKey;
createMinioClient();
}
/**
* 创建基于Java端的MinioClient
*/
public void createMinioClient() {
try {
if (null == minioClient) {
log.info("开始创建 MinioClient...");
minioClient = MinioClient
.builder()
.endpoint(endpoint)
.credentials(accessKey, secretKey)
.build();
log.info("创建完毕 MinioClient...");
}
} catch (Exception e) {
log.error("MinIO服务器异常:", e);
}
}
/**
* 获取上传文件前缀路径
*
* @return {@link String}
*/
public String getBasisUrl(String bucketName) {
return endpoint + SEPARATOR + bucketName + SEPARATOR;
}
/****************************** Operate Bucket Start ******************************/
/**
* 启动SpringBoot容器的时候初始化Bucket
* 如果没有Bucket则创建
*/
@SneakyThrows(Exception.class)
private void createBucket(String bucketName) {
if (!bucketExists(bucketName)) {
minioClient.makeBucket(MakeBucketArgs.builder().bucket(bucketName).build());
}
}
/**
* 判断Bucket是否存在,true:存在,false:不存在
*
* @return
*/
@SneakyThrows(Exception.class)
public boolean bucketExists(String bucketName) {
return minioClient.bucketExists(BucketExistsArgs.builder().bucket(bucketName).build());
}
/**
* 获得Bucket的策略
*
* @param bucketName
* @return
*/
@SneakyThrows(Exception.class)
public String getBucketPolicy(String bucketName) {
return minioClient.getBucketPolicy(GetBucketPolicyArgs.builder().bucket(bucketName).build());
}
/**
* 获得所有Bucket列表
*
* @return
*/
@SneakyThrows(Exception.class)
public List<Bucket> getAllBuckets() {
return minioClient.listBuckets();
}
/**
* 根据bucketName获取其相关信息
*
* @param bucketName
* @return
*/
@SneakyThrows(Exception.class)
public Optional<Bucket> getBucket(String bucketName) {
return getAllBuckets().stream().filter(b -> b.name().equals(bucketName)).findFirst();
}
/**
* 根据bucketName删除Bucket,true:删除成功; false:删除失败,文件或已不存在
*
* @param bucketName
*/
@SneakyThrows(Exception.class)
public void removeBucket(String bucketName) {
minioClient.removeBucket(RemoveBucketArgs.builder().bucket(bucketName).build());
}
/****************************** Operate Bucket End ******************************/
/****************************** Operate Files Start ******************************/
/**
* 判断文件是否存在
*
* @param bucketName 存储桶
* @param objectName 文件名
* @return
*/
public boolean isObjectExist(String bucketName, String objectName) {
boolean exist = true;
try {
minioClient.statObject(StatObjectArgs.builder().bucket(bucketName).object(objectName).build());
} catch (Exception e) {
exist = false;
}
return exist;
}
@SneakyThrows(Exception.class)
public StatObjectResponse getStatObject(String bucketName, String objectName) {
return minioClient.statObject(StatObjectArgs.builder().bucket(bucketName).object(objectName).build());
}
/**
* 判断文件夹是否存在
*
* @param bucketName 存储桶
* @param objectName 文件夹名称
* @return
*/
public boolean isFolderExist(String bucketName, String objectName) {
boolean exist = false;
try {
Iterable<Result<Item>> results = minioClient.listObjects(
ListObjectsArgs.builder().bucket(bucketName).prefix(objectName).recursive(false).build());
for (Result<Item> result : results) {
Item item = result.get();
if (item.isDir() && objectName.equals(item.objectName())) {
exist = true;
}
}
} catch (Exception e) {
exist = false;
}
return exist;
}
/**
* 根据文件前缀查询文件
*
* @param bucketName 存储桶
* @param prefix 前缀
* @param recursive 是否使用递归查询
* @return MinioItem 列表
*/
@SneakyThrows(Exception.class)
public List<Item> getAllObjectsByPrefix(String bucketName,
String prefix,
boolean recursive) {
List<Item> list = new ArrayList<>();
Iterable<Result<Item>> objectsIterator = minioClient.listObjects(
ListObjectsArgs.builder().bucket(bucketName).prefix(prefix).recursive(recursive).build());
if (objectsIterator != null) {
for (Result<Item> o : objectsIterator) {
Item item = o.get();
list.add(item);
}
}
return list;
}
/**
* 获取文件流
*
* @param bucketName 存储桶
* @param objectName 文件名
* @return 二进制流
*/
@SneakyThrows(Exception.class)
public InputStream getObject(String bucketName, String objectName) {
log.info("this is getObject");
log.info("bucketName = " + bucketName);
log.info("objectName = " + objectName);
StatObjectResponse statObjectResponse = minioClient.statObject(StatObjectArgs.builder().bucket(bucketName).object(objectName).build());
log.info("statObjectResponse = {}", statObjectResponse);
GetObjectArgs objectArgs = GetObjectArgs.builder().bucket(bucketName)
.object(objectName).build();
GetObjectResponse getObjectResponse = minioClient.getObject(objectArgs);
log.info("getObjectResponse = {}", getObjectResponse);
if (statObjectResponse == null) {
log.info("statObjectResponse is null");
return null;
}
InputStream stream = minioClient.getObject(GetObjectArgs.builder().bucket(bucketName).object(objectName).build());
log.info("stream = " + stream);
return stream;
}
/**
* 断点下载
*
* @param bucketName 存储桶
* @param objectName 文件名称
* @param offset 起始字节的位置
* @param length 要读取的长度
* @return 二进制流
*/
@SneakyThrows(Exception.class)
public InputStream getObject(String bucketName, String objectName, long offset, long length) {
return minioClient.getObject(
GetObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.offset(offset)
.length(length)
.build());
}
/**
* 文件下载
*
* @param bucketName 存储bucket名称
* @param fileName 文件名称
* @param res response
* @return Boolean
*/
public void download(String bucketName, String fileName, HttpServletResponse res) {
GetObjectArgs objectArgs = GetObjectArgs.builder().bucket(bucketName)
.object(fileName).build();
try (GetObjectResponse response = minioClient.getObject(objectArgs)) {
byte[] buf = new byte[1024];
int len;
try (FastByteArrayOutputStream os = new FastByteArrayOutputStream()) {
while ((len = response.read(buf)) != -1) {
os.write(buf, 0, len);
}
os.flush();
byte[] bytes = os.toByteArray();
res.setCharacterEncoding("utf-8");
//设置强制下载不打开
res.setContentType("application/force-download");
res.addHeader("Content-Disposition", "attachment;fileName=" + fileName);
try (ServletOutputStream stream = res.getOutputStream()) {
stream.write(bytes);
stream.flush();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取路径下文件列表
*
* @param bucketName 存储桶
* @param prefix 文件名称
* @param recursive 是否递归查找,false:模拟文件夹结构查找
* @return 二进制流
*/
public Iterable<Result<Item>> listObjects(String bucketName, String prefix,
boolean recursive) {
return minioClient.listObjects(
ListObjectsArgs.builder()
.bucket(bucketName)
.prefix(prefix)
.recursive(recursive)
.build());
}
/**
* 上传文件
* 使用MultipartFile进行文件上传
*
* @param bucketName 存储桶
* @param file 文件名
* @param objectName 对象名
* @return {@code ObjectWriteResponse response = uploadFile("my-bucket", file, "test.png");
* // 文件的校验标识(MD5 或 ETag 算法生成)。
* // 可以用来验证文件是否完整、是否被篡改。
* // 示例:"fba9dede5f27731c9771645a39863328"
* System.out.println(response.etag());
*
* // 一个对象可以有多个版本,比如 file.txt 被覆盖上传时,旧版本不会丢失,而是有不同的 versionId。这样可以“回滚”。
* // 示例:"3/L4kqtJl40Nr8X8gdRQBpUMLUo"
* System.out.println(response.versionId());
*
* // 上传到的 bucket 名字。
* // 示例:"my-bucket"
* System.out.println(response.bucket());
*
* // 上传后的对象名(路径+文件名)
* System.out.println(response.object());}
*/
@SneakyThrows(Exception.class)
public ObjectWriteResponse uploadFile(String bucketName, MultipartFile file,
String objectName) {
InputStream inputStream = file.getInputStream();
// 执行上传,返回 ObjectWriteResponse,包含文件在 MinIO 的写入结果(etag、版本号等)
return minioClient.putObject(
// MinIO Java SDK 的上传参数构建器,链式设置 bucket、object 等属性。
PutObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.contentType(file.getContentType())
// 第一个参数:输入流(要上传的内容)。
// 第二个参数:流的长度(这里用 inputStream.available(),表示当前可读字节数)。
// 第三个参数:-1 表示分片大小(分成多片上传,自动选择合适的分片大小,默认通常是 5MB 起步)。
.stream(inputStream, inputStream.available(), -1)
.build());
}
/**
* 文件上传
*
* @param file 文件
* @param bucketName 存储bucket
* @return Boolean
*/
public Boolean uploadFile(MultipartFile file, String fileName, String bucketName) {
try {
PutObjectArgs objectArgs = PutObjectArgs.builder().bucket(bucketName).object(fileName)
.stream(file.getInputStream(), file.getSize(), -1).contentType(file.getContentType()).build();
//文件名称相同会覆盖
ObjectWriteResponse objectWriteResponse = minioClient.putObject(objectArgs);
log.info("this is upload -- objectWriteResponse = {}", objectWriteResponse);
} catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
}
/**
* 上传本地文件
*
* @param bucketName 存储桶
* @param objectName 对象名称
* @param fileName 本地文件路径
*/
@SneakyThrows(Exception.class)
public ObjectWriteResponse uploadFile(String bucketName, String objectName,
String fileName) {
return minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.filename(fileName)
.build());
}
/**
* 通过流上传文件
*
* @param bucketName 存储桶
* @param objectName 文件对象
* @param inputStream 文件流
*/
@SneakyThrows(Exception.class)
public ObjectWriteResponse uploadFile(String bucketName, String objectName, InputStream inputStream) {
return minioClient.putObject(
PutObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.stream(inputStream, inputStream.available(), -1)
.build());
}
/**
* 创建文件夹或目录
*
* @param bucketName 存储桶
* @param objectName 目录路径
*/
@SneakyThrows(Exception.class)
public ObjectWriteResponse createDir(String bucketName, String objectName) {
return minioClient.putObject(
PutObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.stream(new ByteArrayInputStream(new byte[]{}), 0, -1)
.build());
}
/**
* 获取文件信息, 如果抛出异常则说明文件不存在
*
* @param bucketName 存储桶
* @param objectName 文件名称
*/
@SneakyThrows(Exception.class)
public String getFileStatusInfo(String bucketName, String objectName) {
return minioClient.statObject(
StatObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.build()).toString();
}
/**
* 拷贝文件
*
* @param bucketName 存储桶
* @param objectName 文件名
* @param srcBucketName 目标存储桶
* @param srcObjectName 目标文件名
*/
@SneakyThrows(Exception.class)
public ObjectWriteResponse copyFile(String bucketName, String objectName,
String srcBucketName, String srcObjectName) {
return minioClient.copyObject(
CopyObjectArgs.builder()
.source(CopySource.builder().bucket(bucketName).object(objectName).build())
.bucket(srcBucketName)
.object(srcObjectName)
.build());
}
/**
* 删除文件
*
* @param bucketName 存储桶
* @param objectName 文件名称
*/
@SneakyThrows(Exception.class)
public void removeFile(String bucketName, String objectName) {
minioClient.removeObject(
RemoveObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.build());
}
/**
* 批量删除文件
*
* @param bucketName 存储桶
* @param keys 需要删除的文件列表
* @return
*/
public void removeFiles(String bucketName, List<String> keys) {
List<DeleteObject> objects = new LinkedList<>();
keys.forEach(s -> {
objects.add(new DeleteObject(s));
try {
removeFile(bucketName, s);
} catch (Exception e) {
log.error("批量删除失败!error:{}", e);
}
});
}
/**
* 获取文件外链
*
* @param bucketName 存储桶
* @param objectName 文件名
* @param expires 过期时间 <=7 秒 (外链有效时间(单位:秒))
* @return url
*/
@SneakyThrows(Exception.class)
public String getPresignedObjectUrl(String bucketName, String objectName, Integer expires) {
GetPresignedObjectUrlArgs args = GetPresignedObjectUrlArgs.builder().expiry(expires).bucket(bucketName).object(objectName).build();
return minioClient.getPresignedObjectUrl(args);
}
/**
* 获得文件外链
*
* @param bucketName
* @param objectName
* @return url
*/
@SneakyThrows(Exception.class)
public String getPresignedObjectUrl(String bucketName, String objectName) {
GetPresignedObjectUrlArgs args = GetPresignedObjectUrlArgs.builder()
.bucket(bucketName)
.object(objectName)
.method(Method.GET).build();
return minioClient.getPresignedObjectUrl(args);
}
/**
* 将URLDecoder编码转成UTF8
*
* @param str
* @return
* @throws UnsupportedEncodingException
*/
public String getUtf8ByURLDecoder(String str) throws UnsupportedEncodingException {
String url = str.replaceAll("%(?![0-9a-fA-F]{2})", "%25");
return URLDecoder.decode(url, "UTF-8");
}
/**
* 从桶中下载文件到本地文件
*
* @param bucketName
* @param fromPath
* @param toPath
* @return
*/
public boolean downloadFile(String bucketName, String fromPath, String toPath) {
log.info("从桶:" + bucketName + "中将" + fromPath + "文件下载到:" + toPath);
boolean result = false;
try {
minioClient.downloadObject(
DownloadObjectArgs.builder()
.bucket(bucketName)
.object(fromPath)
.filename(toPath)
.build());
result = true;
} catch (Exception e) {
log.error("从桶:" + bucketName + "中将" + fromPath + "文件下载到:" + toPath + "错误!");
e.printStackTrace();
}
return result;
}
/****************************** Operate Files End ******************************/
}1.10.4.2 MinIO 的访问控制(权限/ACL/策略)
新建一个 bucket 时,默认是 私有 的:
任何没有身份认证的请求(比如浏览器直接打开 URL)都会 403 Forbidden;
只有用 AccessKey + SecretKey(就是你在配置文件里写的账号密码)发起的请求,才能读/写。
Bucket Policy
你也可以在 MinIO 控制台或用 mc 命令行,设置某个 bucket 或者 object 的权限:
readonly(允许匿名读取)writeonly(允许匿名上传)none(完全私有)
例如:
mc policy set none myminio/my-bucket1.10.5 其他图片传输方式
除了 Base64 编码和字节流,还有其他一些常见的图片传输方式:
- 图像 CDN(内容分发网络):
- 使用 CDN 将图像分发到多个地理位置的服务器,提高访问速度和可靠性。CDN 会自动缓存图像,减少服务器负担。
- WebP 格式:
- WebP 是一种现代图像格式,提供更好的压缩率和图像质量。在支持的浏览器中使用 WebP,可以显著减少图像大小,提高加载速度。
- 懒加载(Lazy Loading):
- 仅在用户滚动到视口时加载图像,从而减少初始加载时间和带宽使用。这对于包含大量图像的页面尤其有效。
1.10.6 文件传输方式结论
| 特性 / 方式 | MinIO(对象存储) | Base64 编码 | 字节流(Byte Stream) | URL 静态资源映射 |
|---|---|---|---|---|
| 本质 | 在自己服务器或云上搭建的对象存储服务(兼容 S3 API) | 将二进制数据转为可打印的文本编码(A–Z,a–z,0–9,+,/) | 数据在内存/网络传输中的原始二进制形式 | Web 服务器直接映射本地目录作为静态资源 |
| 主要用途 | 文件持久化存储、分布式存储、权限管理 | 在不支持二进制传输的环境下传输文件 | 读写文件、网络传输、流式处理 | 对外直接提供文件访问(图片、视频、文档) |
| 访问方式 | API/SDK 调用或签名 URL 访问 | 作为文本嵌入 JSON、HTML、XML 等 | 程序内直接读写字节数组或输入输出流 | 浏览器或客户端直接访问 URL |
| 安全性 | 高:支持权限控制、临时签名 URL、防盗链 | 中:本身不加密,安全取决于传输通道 | 中:需要结合传输协议(HTTPS、加密流) | 低:默认公开访问,需额外做鉴权 |
| 性能 | 中:多一层 API 调用,吞吐量取决于 MinIO 配置 | 低:数据量增大约 33%,CPU 编码解码开销 | 高:原始数据处理速度快 | 高:直接由 Web 服务器返回文件 |
| 扩展性 | 高:支持分布式、集群、海量文件 | 低:不适合大文件,体积膨胀严重 | 高:通用,任何大小文件都能处理 | 低-中:多机需要额外文件同步 |
| 文件大小限制 | 理论可支持超大文件(分片上传) | 适合小文件,太大不现实 | 无限制(受内存/协议限制) | 适合中小型静态资源 |
| 典型场景 | 云存储服务、SaaS 平台、需要权限控制的大规模文件管理 | 前端页面内嵌小图标、接口传输小图片/音频 | 文件 IO、socket 传输、视频流处理 | 网站图片、CSS、JS、可公开访问的文件 |
| 优点 | 跨平台、跨节点、权限灵活、支持分片上传 | 易嵌入文本格式、跨语言传输方便 | 性能好、无额外体积开销、灵活 | 部署简单、访问快、兼容性好 |
| 缺点 | 部署维护成本高、需要额外存储空间 | 体积增加 33%、编码解码慢 | 需要自己管理存储和安全 | 安全性低、缺乏版本控制和高级功能 |
在选择图像传输方式时,开发者需要考虑具体的应用场景和性能需求。Base64 编码适合小图像的嵌入和文本数据的传输,而字节流更适合处理大文件和多种二进制数据。除此之外,URL 引用、CDN、WebP 格式和懒加载等方法也提供了不同的解决方案。了解这些选项可以帮助开发者做出更明智的决策,提升用户体验。
https://www.jb51.net/program/287875lwc.htm
1.11 后端异常(Exception)
Java 异常的继承结构如下:
java.lang.Object
└── java.lang.Throwable
├── java.lang.Exception ← 受检异常(Checked Exception)
│ └── java.lang.RuntimeException ← 运行时异常(Unchecked Exception)
└── java.lang.ErrorException 是所有异常类的父类(除了 Error),它下面分成两大类:
- 受检异常(Checked Exception):直接继承
Exception,但不是RuntimeException的子类。 - 运行时异常(Unchecked Exception):继承
RuntimeException。
| 特性 | Exception(受检异常) | RuntimeException(运行时异常) |
|---|---|---|
| 编译器要求 | 必须显式处理(try-catch 或 throws) |
不要求显式处理 |
| 代表含义 | 可预见、可以恢复的异常,通常是外部原因导致 | 编程逻辑错误、不可预期或不该恢复的错误 |
| 典型例子 | IOException, SQLException, ParseException |
NullPointerException, IllegalArgumentException, IndexOutOfBoundsException |
| 事务回滚(Spring 默认) | 不会自动回滚,除非配置 rollbackFor |
会自动回滚(未捕获时) |
| 用法建议 | 用于业务可控、可恢复的异常 | 用于表示调用方传错参数、逻辑错误等编程失误 |
| 报错阶段 | 如果Maven/Gradle 构建阶段出现受检异常,那就会报错且编译不通过,打包失败。 | 可以正常构建打包,也能启动服务。但运行过程中,如果某个接口触发了异常,就会在那个请求时报错(如果没捕获就返回 500),服务可能继续运行,也可能被异常干掉。 |
1.11.1 RuntimeException(运行时异常)-Java异常
场景:业务前置条件不满足,不想继续执行,也不想强制调用方去 try-catch,直接抛出。
if (order == null) {
throw new RuntimeException("订单不存在");
}在 Spring 事务里,抛出该异常默认会触发事务回滚。
该异常包含几种类型:
1.11.1.1 NullPointerException(空指针异常)
访问了 null 对象的属性或方法:
String name = null;
System.out.println(name.length());1.11.1.2 IllegalArgumentException(参数非法)
方法收到了不合法的参数值:
Thread t = new Thread();
t.setPriority(100); // 优先级只能 1~10
// java.lang.IllegalArgumentException- 场景:传了不在允许范围内的值、不符合格式的字符串等。
1.11.1.3 IndexOutOfBoundsException(越界)
数组或集合下标越界:
List<String> list = Arrays.asList("A", "B");
System.out.println(list.get(5));- 场景:分页、循环、截取字符串/数组时下标计算错误。
1.11.1.4 ArithmeticException(算术异常)
数学运算出错,比如除零:
int x = 5 / 0;- 场景:分母可能来自用户输入、外部数据。
1.11.1.5 ClassCastException(类型转换错误)
把一个对象强制转成不兼容的类型:
Object obj = "Hello";
Integer num = (Integer) obj;- 场景:多态、反射返回类型不匹配。
1.11.1.6 IllegalStateException(状态非法)
对象当前状态不允许执行某个操作:
List<String> list = List.of("A", "B");
list.add("C"); // java.lang.UnsupportedOperationException(它是 IllegalStateException 的兄弟类)- 场景:在已关闭的流上写数据、重复初始化已启动的服务。
1.11.2 Exception(受检异常)-Java异常
受检异常(Checked Exception) 指的是 继承自 java.lang.Exception 但不继承 RuntimeException 的异常。
出现异常时,编译器会强制要求你 显式处理(try-catch 或 throws),否则编译不通过。
添加如下语句,出现受检异常时会自动回滚。
@Transactional(rollbackFor = Exception.class)| 类名 | 场景/说明 |
|---|---|
IOException |
I/O 操作失败,如文件不存在、网络中断 |
FileNotFoundException |
试图打开不存在的文件 |
EOFException |
数据流结束但仍在读取 |
SQLException |
JDBC 数据库访问错误 |
ParseException |
解析字符串到日期或数字时失败 |
ClassNotFoundException |
反射时找不到指定类 |
InstantiationException |
反射创建类实例失败(没有无参构造等) |
IllegalAccessException |
反射访问字段/方法权限不足 |
InterruptedException |
线程被中断 |
NoSuchMethodException |
反射调用时找不到方法 |
NoSuchFieldException |
反射调用时找不到字段 |
CloneNotSupportedException |
对未实现 Cloneable 的对象调用 clone() |
URISyntaxException |
字符串不能正确解析为 URI |
TimeoutException |
执行任务超时 |
TransformerException |
XML 转换失败 |
1.11.3 其它框架/库抛出的运行时异常
其它框架/库抛出的异常都是继承自java异常,但不是 JDK 自带的
- Spring MVC 找不到 Controller 方法参数 →
IllegalStateException - Hibernate 查询参数类型不符 →
IllegalArgumentException - JSON 解析错误 → 框架自定义的 RuntimeException 子类
1.12 实时通信
1.12.1 短轮询
最基础的实时模拟技术。浏览器以固定的时间间隔(例如每秒)向服务器发送HTTP请求,服务器无论数据是否有更新,都会立即返回响应。
优点
- 实现简单,前端只需定时器
- 兼容性极佳,所有浏览器都支持
缺点
- 大量无效请求,浪费带宽和服务器资源
- 实时性差,延迟取决于轮询间隔
适用场景
对实时性要求不高,但兼容性要求极高的场景。例如:早期的比分直播、后台任务状态查询、后台管理系统中不常变动的状态指示器。
1.12.2 长轮询
短轮询的改进版。浏览器发送请求后,服务器会“挂起”连接,直到有新数据或超时才返回响应。客户端收到响应后立即发起下一次请求。
优点
- 减少无效请求,节省带宽
- 实时性优于短轮询
缺点
- 服务器需维护挂起连接,消耗资源
- 高并发下对服务器挑战大
适用场景
需要较好实时性,但无法使用WebSocket/SSE的场景。例如:消息通知、配置中心(Nacos, Apollo)、Web版QQ/微信的早期消息接收、在线问答的答案推送。
1.12.3 服务器发送事件(SSE)
一种基于HTTP的、标准化的服务器单向推送技术。服务器可以通过一个持久连接,持续向浏览器推送数据流。
优点
- 轻量级,基于标准HTTP
- 浏览器原生支持断线重连
- 实现简单,客户端API友好
缺点
- 严格单向通信(服务器 -> 客户端)
- 低版本IE浏览器不支持
适用场景
所有服务器单向推送数据的场景。例如:股票行情、实时日志、AI聊天打字机效果、体育赛事的实时文字直播、CI/CD流水线的实时日志输出。
1.12.4 WebSocket
一种独立的、基于TCP的全双工通信协议。通过一次HTTP握手升级连接后,建立一个持久的双向通信通道。
优点
- 真正的双向通信,延迟极低
- 消息开销小,节省带宽
- 支持二进制数据传输
缺点
- 实现相对复杂,需处理连接状态
- 可能被部分网络代理或防火墙阻止
适用场景
需要高实时、全双工交互的场景。例如:在线聊天室、协同编辑、多人在线游戏、金融交易应用的实时报价、物联网设备状态的远程监控与控制。
1.12.5 WebTransport
Web实时通信技术的演进并未停止。在WebSocket之后,一个新的API——WebTransport——正在标准化进程中,它预示着下一代实时通信的方向。它构建于HTTP/3和QUIC协议之上,旨在结合WebSocket的便捷与WebRTC的强大功能。
解决队头阻塞
其底层的QUIC协议基于UDP,从根本上解决了TCP的队头阻塞问题,连接更稳定快速。
支持多个数据流
一个连接可以承载多个独立的双向流,非常适合传输不同类型的数据(如游戏中的聊天、音频和状态)。
支持不可靠数据报
除了可靠的流式传输,还支持发送不可靠、无序的数据报,对速度优先于可靠性的场景(如快节奏游戏)是革命性的。
定位与未来
WebTransport不应被视为WebSocket的直接替代品,而是一个功能更强大的继任者。对于需要多个数据流、乱序交付或不可靠消息传递的复杂用例,WebTransport将提供前所未有的能力。它的出现表明,对更底层、更灵活、更高性能的实时通信协议的探索仍在继续。
1.13 Maven
Maven 的本质是一个项目管理和构建自动化工具
pom.xml是Maven 的核心配置文件
Maven生命周期
clean
目的是清除之前构建生成的文件(比如编译后的 target目录)。
pre-clean:执行一些清理前需要完成的工作。clean**:核心阶段**。删除target目录及其所有内容。post-clean:执行一些清理后需要完成的工作。
常用命令:mvn clean
default
最核心、最常用的生命周期,它包含了项目构建的绝大部分步骤
| 阶段 | 说明 | 核心作用 |
|---|---|---|
validate |
验证 | 验证项目是否正确且所有必要信息可用。 |
initialize |
初始化 | 初始化构建状态,例如设置属性或创建目录。 |
generate-sources |
生成源码 | 生成任何需要包含在编译过程中的源代码。 |
process-sources |
处理源码 | 处理源代码,例如过滤一些值。 |
generate-resources |
生成资源 | 生成包含在包中的资源文件。 |
process-resources |
处理资源 | 复制并处理资源文件到目标目录,准备打包。 |
compile |
编译 | 编译项目的源代码。 → 生成 .class文件到 target/classes |
process-classes |
处理类文件 | 编译后处理生成的文件,例如对Java类进行字节码增强。 |
generate-test-sources |
生成测试源码 | 生成测试相关的源代码。 |
process-test-sources |
处理测试源码 | 处理测试源代码。 |
generate-test-resources |
生成测试资源 | 创建测试所需的资源文件。 |
process-test-resources |
处理测试资源 | 复制并处理测试资源到测试目标目录。 |
test-compile |
编译测试源码 | 编译测试源代码。 → 生成测试的 .class文件 |
test |
测试 | 使用合适的单元测试框架(如JUnit)运行测试。 |
prepare-package |
准备打包 | 在打包之前执行任何必要的操作。 |
package |
打包 | 将编译后的代码打包成可分发的格式,如 JAR, WAR。 |
pre-integration-test |
集成测试前 | 在集成测试运行之前执行所需的操作。例如,设置环境。 |
integration-test |
集成测试 | 处理和部署包到集成测试可以运行的环境。 |
post-integration-test |
集成测试后 | 在集成测试运行之后执行所需的操作。例如,清理环境。 |
verify |
验证 | 对集成测试的结果进行检查,以确保满足质量要求。 |
install |
安装 | 先打包后将包额外安装到本地Maven仓库,供本地其他项目依赖。 |
deploy |
部署 | 将最终的包复制到远程仓库,供其他开发人员和项目共享。 |
site
为项目构建一个信息丰富的项目站点HTML
pre-site:执行一些生成站点前需要完成的工作。site**:核心阶段**。生成项目站点文档。post-site:执行一些生成站点后需要完成的工作。site-deploy:将生成的项目站点部署到服务器。
常用命令:mvn site(会在 target/site目录下生成项目报告和文档)
2. 前端
2.1 Vue3
2.1.1 Vue3配置@
设置了src为@别名
Vue: Cannot find module @/utils/axios or its corresponding type declarations.1、需要加入path依赖
@types/node是Typescript的一个声明文件包,用于描述node.js核心模块和常使用的第三方库的类型信息
npm i @types/node2、vite.config.ts配置
// vite.config.ts配置文件
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
// 引入node内置模块path:可以获取绝对路径(找不到模块“path”或其相应的类型声明。ts(2307))
import path from 'path'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [vue()],
resolve: {
alias: {
// (找不到模块“__dirname”或其相应的类型声明。ts(2304))
// node提供的path中的全局变量:__dirname用来获取绝对路径
"@":path.resolve(__dirname,'src')//@ 表示 src
}
}
})
3、tsconfig.json配置
在该配置文件中在compilerOptions添加配置,这一步的作用是让IDE可以对路径进行智能提示
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
},
},
}4、tsconfig.app.json配置(重点)
也一样要加上,webstorm才不会报红
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
},
},
}5、src/vite-env.d.ts
/// <reference types="vite/client" />
declare module "*.vue" {
import type { DefineComponent } from "vue";
const vueComponent: DefineComponent<{}, {}, any>;
export default vueComponent;
}配置完后,需要重启
2.2 Vue2
2.2.1 调用外部组件
需要把外部组件挂到所有组件实例的 $ 上:main.js全局导入
import publicUtils from "@/utils/commonFunction/publicUtils";
Vue.prototype.$pubUtils = publicUtils;然后就可以在模板上用$pubUtils
2.2.2 Vue父组件传递子组件
props传递,refs传递(可以获取子组件定义的所有实例,data、method)
2.3 ElementUI
2.3.1 表单验证与v-if冲突
如果在el-form里写一个div块,用v-if控制这个块的显示与否,要注意表单验证加载和显示的时机不能冲突,因为v-if会操作DOM删减,可能会影响表单加载
2.4 Utils
2.4.1 封装前端判空api
// 工具类方法-- 检查是否为空(Date、string、number,数字0是不为空的)
function method_isEmpty(item) {
// 1. null / undefined 类型 是空
if (item === null || item === undefined) {
return false;
}
// 2. Date:合法日期才算非空
if (item instanceof Date) {
return !isNaN(item.valueOf());
}
// 3. 字符串:去掉空格后非空
if (typeof item === "string") {
return item.trim() !== "";
}
// 4. 数字:NaN 视为“空”,其它数字(包括 0)都算非空
if (typeof item === "number") {
return !Number.isNaN(item);
}
// 5. 数组:长度为 0 视为空
if (Array.isArray(item)) {
return item.length !== 0;
}
// 6. 布尔:true/false 都算非空
if (typeof item === "boolean") {
return true;
}
// 7. BigInt:任何值都算非空
if (typeof item === "bigint") {
return true;
}
// 8. Map / Set:有元素才算非空
if (item instanceof Map || item instanceof Set) {
return item.size !== 0;
}
// 9. 对象:没有 own keys 的纯空对象视为空
if (typeof item === "object") {
return Object.keys(item).length !== 0;
}
// 10. 其它情况默认是空
return false;
}2.5 Js
2.5.1 Tips
- 前端console用+不能输出具体内容,得用,
- formdata在append的时候会把value转成string
- _.cloneDeep采用Lodash纯 js 库,确保新对象与原对象完全独立
let list = res.data && res.data.length > 0 ? [...res.data] : []; 为什么在涉及扩展运算符 ...的时候要考虑[]的情况?
答:因为扩展运算符 ... 只能作用于 可迭代对象(通常是数组、字符串、Set 等),如果你对 undefined、null 或者其它非可迭代类型使用 [...res.data],就会抛出类似:TypeError: res.data is not iterable
JavaScript中for...in和for...of的区别?
答:for in是用于遍历对象的键(key或者索引),可遍历的数据结构有普通对象、数组的索引、字符的索引(字符串形式)、类数组对象的索引(Array-like Objects)、自定义构造函数实例及其原型链上的可枚举属性。而for of是用于遍历可迭代对象的值(value),可遍历的数据结构有数组、字符串、Map、Set、类数组对象、生成器、TypedArray、自定义可迭代对象
2.5.2 Js深拷贝
浅拷贝仅复制object的第一层属性(对最外层的键值对进行拷贝,不会递归复制内部内容),嵌套对象仍共享内存引用。如下所示, city和zip是不会被复制的。
const person = {
id: 101,
name: 'Bob',
address: {
city: 'Shanghai',
zip: '200000',
},
};| 方法名 | 是否支持嵌套 | 是否支持特殊类型(Date、RegExp、Map 等) | 是否支持循环引用 | 优点 | 缺点 / 限制 |
|---|---|---|---|---|---|
JSON.parse(JSON.stringify(obj)) |
是 | 否 | 否 | 简单、原生、适合纯数据结构 | 丢失函数、undefined、Date 等 |
| 手写递归函数 | 是 | 基础版不支持,进阶版可支持 | 基础版不支持 | 原理清晰、可扩展 | 实现复杂,需处理类型 & 循环引用 |
_.cloneDeep(Lodash) |
是 | 是 | 是 | 支持复杂结构、稳定性高 | 需引入第三方库 |
structuredClone(原生) |
是 | 支持 Date、Map、Set、Blob 等 | 是 | 原生支持、性能好、语义清晰 | 不支持函数、DOM 节点,需现代环境支持 |
2.6 打包
如何在浏览器里直接看到完整 .vue 源码
控制台 - Sources
- Sources →
webpack://→<项目名>→src/views/PublicSentimentSystem/SentimentFileUpload/ - 打开
SingleSentimentDataLabelingView.vue(不带查询参数)。
- Sources →
如果找不到完整文件
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| vue-clipboard2/3(第三方库) | 简单,指令式,配合 UI 框架好用 | 需要额外安装依赖 | Vue2/3 项目常用 |
| execCommand | 不依赖第三方库 | API 逐渐废弃,兼容性差 | 兜底方案 |
| navigator.clipboard | 现代 API,写法简洁 | 需要 HTTPS,旧浏览器不支持 | 新项目,安全场景 |
| clipboard.js(第三方库) | 原生 JS 库,成熟稳定 支持事件回调(成功/失败) 不依赖 Vue,可通用 | 需要手动封装到 Vue 指令或方法 代码比 vue-clipboard2 多一些 | Vue2/Vue3/原生项目都可用,尤其是想自己灵活控制逻辑时 |
2.8 React
2.8.1 使用@配置src目录
很多 React/Vite 工程里,编辑器/tsserver 对 src 下文件使用的是 tsconfig.app.json,如果 tsconfig.app.json 没有 extends 到根 tsconfig 的 paths(或者你编辑器没按根 tsconfig 作为工程入口),就会出现“导入能跑,但类型解析断裂”的怪现象。
// tsconfig.app.json
{
//以下两个配置一个即可
"extends": "./tsconfig.json",
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": [
"src/*"
],
"@": [
"src"
]
},
}
}3. 大模型
3.1 LLM基础知识
3.1.1 LLM的类型
结构化解析大模型(Structured Parsing LLM)
– 输出结构化数据,用于信息抽取、Agent参数解析、日志分析、自然语言转SQL、API调用参数生成等
嵌入大模型(Embedding Model)
– 生成高维语义向量,用于相似度计算,RAG核心部分
指令微调型(Instruction-tuned LLM)
多模态模型(Multimodal LLM)
Agent 型模型(Tool-use LLM)
3.1.2 基本概念
3.1.2.1 LLM回答错误
- 提示词工程(没问清楚)
- 检索增强生成RAG(缺乏相关知识)
- 微调(能力不足)
- 私有化部署
3.1.2.2 向量数据库
用于存储和检索向量数据的数据库系统,关注向量数据的特性和相似性
数据被表示为向量形式(基本单位),可以是数字、⽂本、图像或其他类型的数据
通过余弦距离、点积计算相似度;数据库索引和查询算法的效率明显⾼于传统数据库
主流的向量数据库:
3.2 检索增强生成
参考资料 [面向大语言模型的检索增强生成技术:综述 译] | 宝玉的分享
3.2.1 RAG基本概念
- 让大模型先查资料再写答案,将外部知识库检索到的证据拼装进提示词,让模型更准确,减少幻觉。
- 是
3.2.2 RAG流程
3.2.2.1 原始RAG的流程
索引 提取文本数据;分块;编码并创建索引(原始文本与Embedding之间)
检索 对问题编码;选取语料库中与问题最相关的块(向量相似度)作为补充信息
生成 将问题与语料库输入LLM,生成答案,可选择是否使用补充信息和历史对话
挑战:检索质量(内容不相关);回答质量(虚构答案/答非所问);增强过程合理性(相关性排名/语言风格/过度依赖增强信息)
3.2.2.2 高级RAG的流程
检索预处理 – 优化数据索引质量
- 提升数据粒度:优化文本的清晰度、上下文和正确性,提高系统的效率和可靠性
- 优化索引结构:调整数据块大小、改变索引路径和加入图结构信息
- 添加元数据:引入元数据(日期、用途、章节)进行初步筛选,提高检索的效率和准确性
- 对齐优化:创建适合用每篇文档回答的问题,解决不同文档间的一致性问题
- 混合检索:融合了关键词搜索、语义搜索和向量搜索等多种技术
Embedding
- 微调嵌入:让检索到的内容与查询之间的相关性更加紧密
- 动态嵌入:根据单词出现的上下文进行调整,为每个单词提供不同的向量表示
检索后处理 – 对检索到的内容进行额外处理
- 重新排序:将最相关的信息置于提示的前后边缘
- Prompt压缩:突出关键信息,压缩无关的上下文
- RAG管道优化:优化检索过程,达到效率与信息丰富度的平衡
- StepBack-prompt:LLM 在处理具体案例时能够退一步,转而思考背后的普遍概念或原则
- HyDE(Hypothetical Document Embeddings):首先响应查询生成一个假设性文档(答案),然后将其嵌入,并利用此嵌入代替原始查询进行检索,而非单纯依赖于查询的嵌入相似性
- 混合搜索、递归检索与查询、子查询
3.2.2.3 模块化RAG
- 集成了各种方法来丰富功能模块
- 搜索模块
- 记忆模型
- 额外生成模块
- 任务适应模块
- 对齐模块
- 验证模块
3.3 提示词工程
3.3.1 基本概念
Prompt & Completion:LLM的输入和输出
Temperature:用于控制LLM生成结果随机性的参数,0~1之间,0的随机性最低,不太可能⽣成意想不到或不寻常的词;1的预测随机性会最高,会产⽣更有创意、多样化的⽂本。
System Prompt:在整个会话过程中持久地影响模型的回复,一般只有一个,来对模型进⾏⼀些初始化设定
加载LLM API
import os from detenv import load_dotenv, find_dotenv # 读取本地环境变量 _ = load_dotenv(find_dotenv())3.3.2 Prompt Engingneering
3.3.2.1 Prompt 设计原则
编写清晰、具体的指令
- 使⽤```,”””,< >, ,:等分隔符清晰地表示输⼊的不同部分
- 避免提示词注入(Prompt Rejection):用户输入的文本可能包含与预设Prompt相冲突的内容
- 寻求结构化的输出:按照某种格式组织内容(JSON、HTML)
- 要求模型检查是否满⾜条件:若模型不能满足任务条件,则停止执行
- 提供少量实例:在执行前给模型提供参考样例,让其了解要求和期望输出
- 使⽤```,”””,< >, ,:等分隔符清晰地表示输⼊的不同部分
给模型时间去思考
指定完成任务所需的步骤
指导模型在下结论之前找出⼀个⾃⼰的解法
- 避免幻觉(Hallucination):模型生成的内容与现实世界事实或用户输入不一致的现象
3.4 大模型排名
https://artificialanalysis.ai/
以2025 年 12 月公开可查的主流榜单为依据,覆盖三类“最新排名”口径:
- 人类偏好/真实对话体验:LMArena(Chatbot Arena)按 Elo 评分给出多赛道榜单(Text / WebDev / Vision 等)。(LMArena)
- 标准化基准测评:Vellum 汇总 GPQA(高难推理)、AIME(数学)、SWE-Bench(代理式编码)、HLE(综合)等“非饱和”榜单。(vellum.ai)
- 聚合指数:Artificial Analysis Intelligence Index v3.0(10 项评测聚合)给出“总体智能”梯队与头部位置描述。
注意:不同榜单测的是不同能力维度,“最新排名”也会随模型版本滚动更新。以下给出分场景排名与各模型擅长点(结合其在对应赛道/基准的领先位置)。
3.4.1 大模型排名
1)文本对话综合(LMArena Text)
Top 10(Elo/Score,越高越好):(LMArena)
| 排名 | 模型 | Score |
|---|---|---|
| 1 | gemini-3-pro | 1490 |
| 2 | gemini-3-flash | 1478 |
| 3 | grok-4.1-thinking | 1477 |
| 4 | claude-opus-4.5-thinking-32k | 1469 |
| 5 | claude-opus-4.5 | 1467 |
| 6 | grok-4.1 | 1464 |
| 7 | gemini-3-flash (thinking-minimal) | 1463 |
| 8 | gpt-5.1-high | 1455 |
| 9 | gemini-2.5-pro | 1451 |
| 10 | claude-sonnet-4.5-thinking-32k | 1450 |
2)Web 开发/前端工程(LMArena WebDev)
Top 10:(LMArena)
| 排名 | 模型 | Score |
|---|---|---|
| 1 | claude-opus-4.5-thinking-32k | 1520 |
| 2 | gpt-5.2-high | 1484 |
| 3 | claude-opus-4.5 | 1480 |
| 4 | gemini-3-pro | 1478 |
| 5 | gemini-3-flash | 1465 |
| 6 | glm-4.7 | 1449 |
| 7 | gpt-5-medium | 1398 |
| 8 | gpt-5.2 | 1398 |
| 9 | claude-sonnet-4.5-thinking-32k | 1393 |
| 10 | gpt-5.1-medium | 1392 |
3)多模态视觉理解(LMArena Vision)
Top 10:(LMArena)
| 排名 | 模型 | Score |
|---|---|---|
| 1 | gemini-3-pro | 1309 |
| 2 | gemini-3-flash | 1284 |
| 3 | gemini-3-flash (thinking-minimal) | 1268 |
| 4 | gpt-5.1-high | 1249 |
| 5 | gemini-2.5-pro | 1249 |
| 6 | gpt-5.1 | 1239 |
| 7 | chatgpt-4o-latest-20250326 | 1236 |
| 8 | gpt-4.5-preview-2025-02-27 | 1226 |
| 9 | gemini-2.5-flash-image-preview-09-2025 | 1224 |
| 10 | gpt-5-chat | 1223 |
4)高难推理、数学、代理式编码(Vellum 基准榜)
- 推理(GPQA Diamond):GPT 5.2 92.4,Gemini 3 Pro 91.9,GPT 5.1 88.1 等。(vellum.ai)
- 数学(AIME 2025):GPT 5.2 与 Gemini 3 Pro 均为 100;其后 Kimi K2 Thinking、GPT oss 20b、OpenAI o3。(vellum.ai)
- 代理式编码(SWE-Bench):Claude Sonnet 4.5 82,Claude Opus 4.5 80.9,GPT 5.2 80,Gemini 3 Pro 76.2。(vellum.ai)
- 综合(Humanity’s Last Exam):Gemini 3 Pro 45.8,Kimi K2 Thinking 44.9,GPT-5 35.2 等。(vellum.ai)
5)总体智能(Artificial Analysis Intelligence Index v3.0)
Artificial Analysis 的 Q3 2025 报告指出:GPT-5 (high) 在该聚合指数上领先(68),其后为 Grok 4(65)、Claude 4.5 Sonnet (Thinking)(63)、Gemini 2.5 Pro(60)等。
3.4.2 各自优势
Gemini 3 Pro(Google)
- 强项 1:综合对话体验:在 LMArena Text 排名第 1。(LMArena)
- 强项 2:多模态视觉理解:在 LMArena Vision 排名第 1;在 Vellum 的多语推理(MMMLU)也处于领先梯队。(LMArena)
- 适用场景:通用助手、图文问答、跨语种知识问答、产品化“默认模型”。
Claude Opus 4.5 / Claude Sonnet 4.5(Anthropic)
- 强项 1:Web 开发与工程产出:Opus 4.5 Thinking 在 LMArena WebDev 排名第 1。(LMArena)
- 强项 2:代理式软件工程(SWE-Bench):Sonnet 4.5 在 Vellum 的 SWE-Bench 排名靠前(82)。(vellum.ai)
- 适用场景:前端/全栈开发、代码审阅与重构、基于 Issue 的修复代理、长链路工程任务。
GPT 5.2 / GPT 5.x(OpenAI)
- 强项 1:高难推理(GPQA):GPT 5.2 在 Vellum 的 GPQA Diamond 居首。(vellum.ai)
- 强项 2:数学能力(AIME 2025):GPT 5.2 为满分梯队。(vellum.ai)
- 强项 3:WebDev 竞争力强:gpt-5.2-high 在 LMArena WebDev 排名第 2。(LMArena)
- 适用场景:复杂推理、严谨问答、数学/算法、需要强一致性的业务推断与工具调用规划。
Grok 4 / Grok 4.1(xAI)
- 强项 1:对话榜单高位:在 LMArena Text 中 grok-4.1-thinking 排名第 3,grok-4.1 也处于前列。(LMArena)
- 强项 2:总体智能指数靠前:在 Artificial Analysis 报告中位列 GPT-5 (high) 之后的头部梯队。
- 适用场景:偏开放式对话、综合型任务、需要较强推理但不以工程交付为主的场景。
Kimi K2 Thinking 等(其他厂商代表)
- 强项:考试型与综合基准:在 Vellum 的 AIME(99.1)与 Humanity’s Last Exam(44.9)上进入头部梯队。(vellum.ai)
- 适用场景:高难考试风格题、长链路推理、复杂知识整合(需结合实际可用的 API/部署条件)。
3.4.3 适用类型
通用“默认模型”
- 优先:Gemini 3 Pro(Text + Vision 均榜首)(LMArena)
代码与 Web 工程交付
高难推理 / 数学 / 严谨问答
- 优先:GPT 5.2(GPQA 榜首,AIME 满分梯队)(vellum.ai)
MCP协议
workflow
Agent/Multi-Agent
4. 后端架构分析
4.1 后端架构分析(可修改)
1. 项目背景与整体概述
- 业务目标与痛点
- 核心功能点
- 主要使用场景
2. 技术栈与依赖
- Java 版本、框架(Spring Boot/Spring Cloud/MyBatis 等)
- 数据库(MySQL/PostgreSQL/MongoDB 等)
- 消息中间件(Kafka/RabbitMQ)
- 缓存(Redis)
- 其他组件(Feign、Gateway、ZooKeeper 等)
3. 系统架构与模块划分
- 高层架构图(微服务/单体)
- 各模块职责
- 模块间调用关系
4. 核心业务流程
- 用例示例:用户下单/登录鉴权流程
- 时序图或流程图(Controller → Service → Repository)
- 关键接口说明(请求参数、返回结果、HTTP 状态码)
5. 典型代码解析
- Controller 层:如何接收请求并做参数校验
- Service 层:业务逻辑拆解与事务管理
- Repository/DAO 层:数据库访问示例
- 测试用例:单元测试与集成测试演示
6. 异常处理与日志规范
- 统一异常体系(自定义异常、全局异常处理)
- 日志级别与内容(INFO/DEBUG/ERROR)
- 链路追踪(TraceId/SpanId)
7. 性能与优化
- 缓存设计与使用(本地缓存 vs 分布式缓存)
- 异步执行与线程池配置
- 限流、降级与熔断策略(Sentinel/Resilience4j)
8. 安全与权限控制
- 鉴权方式(JWT/OAuth2)
- 权限注解(@PreAuthorize/自定义注解)
- 常见安全漏洞防护(SQL 注入、XSS、CSRF)
9. 部署与运维
- 打包与发布(Maven/Docker)
- 容器化/Kubernetes 配置
- 持续集成与持续交付(Jenkins/GitHub Actions)
- 监控与报警(Prometheus+Grafana、ELK)
10. 总结与答疑
- 项目亮点与难点回顾
- 下一步优化方向
- 开放提问
17分支
104分支
分支概述与背景
业务目标
通过角色权限控制管理用户访问不同系统,确保不同用户在系统中的操作权限符合其身份和职责。核心功能
用户与角色之间的权限映射,确保只有授权的用户能够访问特定路由和执行特定操作。
RBAC(Role-Based Access Control)角色权限管理
基本概念
- 角色:定义不同的系统角色(如管理员、开发者、测试员等),并为其分配一组权限点。
- 权限点:权限点对应特定的功能或操作,通常关联到具体的前端路由。
权限控制逻辑
- 角色-权限映射:前端需要访问某个路由时,前端设置所需的权限点,系统通过角色与权限点的关系来判断用户是否有权访问该路由。
- 多角色与多权限:每个用户可以有多个角色,而每个角色可以拥有多个权限点,因此,用户在某个特定场景下所拥有的权限是多维度的。
| 用户 | 角色 | 权限点 | 路由 |
|---|---|---|---|
| 11182984 | 超管 | 基础权限-平台1 | /FluencySystem/home |
| 11132167 | 管理员 | 基础权限-平台2 | /FluencySystem/… |
| … | 开发者 | 高级权限-系统1 | … |
| … | 测试员 | 高级权限-系统2 | … |
一个用户会被分配多个角色,一个角色会拥有多个权限点,一个权限点允许访问指定的前端路由
数据表设计
PermissionPointMapDao
权限点和路由
| 权限点id | 权限点描述 | 路由路径信息 | 创建时间 | 更新时间 | |
|---|---|---|---|---|---|
| id | permissionPointId | permissionPointDescription | routingPathInfo | createTime | updateTime |
RolePermissionDetailDao
角色和权限点
| 角色类型id | 权限点id | 创建时间 | 更新时间 | |
|---|---|---|---|---|
| id | roleTypeId | permissionPointId | createTime | updateTime |
UserRoleDetailDao
用户和角色
| 用户工号 | 角色类型ID | 创建时间 | 更新时间 | |
|---|---|---|---|---|
| id | userUuid | roleTypeId | createTime | updateTime |
RoleTypeMapDao
角色详细信息
| 适用平台 | 角色名称 | 角色描述 | 角色编码 | 创建时间 | 更新时间 | |
|---|---|---|---|---|---|---|
| roleTypeId | applicablePlatform | roleName | roleDescription | roleTypeCode | createTime | updateTime |
UserBasicInfoDao
用户详细信息,包含工号、姓名、部门、上级等
前端业务
任意页面-管理员页面-用户管理系统
使用方法:前端设置所需的权限点,去找到对应这些权限点的角色,然后看用户的角色list和角色-权限映射表中具有本次要求权限的角色集合是否有交集
权限检查机制
前端权限控制
- 根据用户角色和权限点来动态展示界面元素。
- 根据前端传递的权限点,判断用户是否可以访问该路由。
- 如果没有权限,要提示用户发单申请(VR250613-176)
后端权限校验
- 每当用户请求访问敏感资源或执行敏感操作时,后端根据用户的角色与权限点进行校验。
- 若用户权限不足,后端应返回适当的错误信息。
- 待补充
扩展与维护
角色与权限的修改与扩展
- 如何新增角色、修改权限点,保证现有系统不受影响。任意页面-管理员页面-用户管理系统,通过可视化界面修改用户拥有的角色、角色详情以及角色与权限点对应关系、权限点和路由对应关系。
支持多平台的权限管理
- 通过
RoleTypeMapDao中的applicablePlatform字段支持跨平台的角色与权限控制。 - 根据不同平台,分配适用的权限角色。
其他
用户管理不涉及token传入,还会结合api接口检查工号是否存在。
其他角色权限管理方式
基于资源的权限控制(RBAC: Resource-Based Access Control)
- 描述:基于角色和资源进行权限控制,每个资源被分配特定权限,角色也可以对不同资源进行细粒度控制。
- 使用场景:适用于访问控制需求复杂的系统,例如,一个页面可能有查看和编辑权限,不同角色可以有不同权限。
- 实现方式:
- 资源划分:每个资源分配不同权限点(例如:
read,write,execute)。 - 用户与资源的权限映射:角色通过资源权限点来控制访问。
- 资源划分:每个资源分配不同权限点(例如:
| 资源 | 权限点 | 角色 | 用户 |
|---|---|---|---|
/home |
查看、编辑 | 超管 | 用户A |
/home |
查看、编辑 | 管理员 | 用户B |
/profile |
查看 | 开发者 | 用户C |
/profile |
编辑 | 测试员 | 用户D |
基于属性的访问控制(ABAC)
描述:通过多个属性(如用户、资源、环境等)来进行权限控制,支持更加灵活的权限管理。
使用场景:适用于权限控制较为复杂的系统,例如根据时间、位置、设备等属性来进行访问判断。
实现方式:
- 权限决策基于以下属性:
- 用户属性(如角色、部门等)
- 资源属性(如资源类型、状态等)
- 环境属性(如访问时间、设备类型等)
- 权限决策基于以下属性:
基于命令的权限控制(CBAC)
描述:权限不仅依赖于角色,还基于特定的命令或操作进行控制。
使用场景:适用于命令级别权限控制,如数据库管理系统中的数据修改操作权限。
实现方式:
- 每个命令(如数据修改、删除)对应一个权限点。
- 用户通过角色与命令的映射来控制对操作的访问。
基于策略的权限控制(PBAC)
描述:基于动态定义的策略进行权限控制,规则通常包括用户、资源和环境等因素。
使用场景:适用于需求变化频繁、策略灵活的权限管理系统。
实现方式:
- 权限控制策略可以动态调整,支持业务逻辑需求变化。
- 策略通常基于PDP(权限决策点)和PEP(权限执行点)模型。
总结与 Q&A
- 主要技术挑战与解决方案
- 后续优化方向(如缓存优化、权限点的动态更新等)
- 开放提问,解答团队成员对角色权限管理的疑问
5. PostgreSQL
5.1 PostgreSQL与MySQL对比
登录命令
psql -h <IP> -p 5432 -U postgres -d postgres
psql -U postgres对应
mysql -h <IP> -P 3306 -u root -p mysql
mysql -u root -p6. Git
6.1 Git操作指南
# 放弃某个未提交的修改
git restore <文件名>
# 正常提交
git commit -m "fix(VR...): (1)修复...;"
# 追加提交
git commit --amend
# 提交待审核(gerrit)
git push origin HEAD:refs/for/<分支>
# 直接提交不审核
git push origin <分支>
# 将修改保存至堆栈进行缓存
git stash
# 将堆栈缓存出栈至工作区,有冲突需要手动处理
git stash pop
# 获取commitId
git rev-parse HEAD
# 等价于:git fetch + git merge(合并)
git pull
# 软回退(一般是Abandon之后复原本地提交)
git reset HEAD^
# 硬重置到远程某个commitID/最新分支
git reset --hard <commitID>
git reset --hard origin/<分支>
# 查看远程所有分支
git branch -r7. 其他
7.1 IDEA插件汇总
Alibaba Java Coding Guidelines(XenoAmess TPM)
Easy Javadoc
element
Git Commit Message Helper
GitToolBox
Loglt
Maven Dependency Helper
Maven Helper
Mybatis-Flex-Helper
QAPlug
Rainbow Brackets
Save Action X
Xcode-Dark Theme
8. 项目案例分析
8.1 项目案例分析-微信小程序websocket优化
查询座位信息的时候用短轮询,一开始的时候就是短轮询,发送定时请求,但是结果会有点卡。主要原因是:接口响应从几百毫秒 飙升到几秒,用户端明显感觉卡顿。
CPU/线程池耗尽:线程池打满,新请求排队,平均响应时间变长
数据库压力:轮询查询的 SQL 多且重复(大部分数据其实没变),缓存命中率低,DB 被大量无效请求拖慢。
带宽浪费:每次都传全量数据(几十 KB 甚至上百 KB),吞吐打满时排队更严重。
改成了ws后端定时推送,但是我还是不满意,就改成了rabbitmq监听数据变化来推送。
背景(启动阶段)
问题:我们做的是一个教室座位预约系统。需求是学生提前预约座位,但随着预约一开放,成千上万的学生同时抢同一个座位,这就导致了系统的高并发和高峰压力。
挑战:最开始我们用数据库查询每个座位的状态,每两秒轮询一次,但这导致了数据库压力过大,且延迟明显。特别是当座位有变化时,轮询的延迟导致前端显示不实时,影响用户体验。
第一次解决方案(短轮询+Redis缓存)
方案:为了缓解数据库压力,我加入了 Redis 缓存,缓存座位的状态(例如:
seat:data:{room|date}:v{ver}),使得查询大部分都可以从 Redis 快速读取。
效果:数据库压力明显减少,缓存命中率提升,读写分离优化了数据库的负载,但问题是轮询间隔还是无法做到实时。每次变化仍需等待 2s 更新。
新的问题:延迟依然存在,当状态变化时,用户看到的座位状态还是会有2秒的延迟。
第二次解决方案(RabbitMQ+WebSocket实时推送)
方案:我们改成了 WebSocket 实时推送座位状态的变化。这样一来,当座位状态变化时,客户端能够立刻收到。但很快就遇到了推送风暴的问题。
具体来说,在高并发时,多个用户同时抢同一个座位,会导致服务端每次有变化就推送消息,这会瞬间淹没 WebSocket 连接与 MQ,甚至导致客户端漏掉消息或状态乱序。
新的问题:服务端推送频繁且数据量大,客户端偶尔会漏帧或显示错误的座位状态。
第三次解决方案(Redis+Lua原子操作,解决并发冲突)
方案:为了防止多个用户同时抢座位时出现超卖问题,我们用 Redis Lua 脚本进行原子操作,保证每个座位的状态只能由一个用户进行操作。
- 读当前座位的状态;
- 判断当前状态是否是
free;- 如果是
free,就进行状态更新并递增版本号;- 更新聚合版本(
aggVer)。
效果:超卖问题被杜绝,并发冲突得到解决。但还是存在消息推送频繁的问题,且前端性能受影响。
新的问题:数据变化仍然太快,WebSocket 与 MQ 频繁推送,前端渲染压力大。
第四次解决方案(小窗口合并 + MQ解耦)
方案:我们引入了 小窗口合并(Coalescing),在 50–100ms 的时间窗口内,把多个座位的变化累加到内存中,等窗口结束后一次性通过 Redis Lua 脚本进行批量更新,并只发送一条合并后的 MQ 消息。
这个方式避免了重复的推送,减少了对 WebSocket 和 MQ 的压力。
效果:消息推送频率大幅降低,数据更新与前端渲染变得更加平稳,内存压力也得到了控制。
新的问题:随着业务的扩展,一天的座位可能会有多个时段,消息量依然庞大,是否会触发 Redis 键爆炸?
第五次解决方案(位图建模 + Redis优化)
方案:我设计了一个新的 位图建模,将每个座位的状态存储为一个 10 位的位图,表示每个时段的预约状态。每个座位的状态都通过
seat:doc:{room|date}:{seatId}来存储一个整天的时段信息。
这样,数据从 每个座位每个时段一个键,变成了 每个座位一天一条文档,极大减少了 Redis 中键的数量。
效果:消息量和 Redis 键的数量大幅减少,避免了键值膨胀的问题,同时前端推送也得到了稳定。
新的问题:客户端是否能继续稳定更新,特别是在大规模并发下,如何做到高效的增量更新?
第六次解决方案(客户端稳定化:WebSocket背压与限速)
方案:为了避免客户端接收过多数据导致卡顿,我们在 WebSocket网关中实现了背压与限速机制。每个客户端的消息队列有上限,如果队列满了,就丢弃中间帧并推送
invalidate,确保客户端始终能保持平稳的消息流。
同时,前端通过 环形缓冲 与 滑动窗口机制,只保存最新的若干秒的数据,避免内存涨得太快。
效果:系统稳定性进一步提升,消息流量得到有效控制,前端响应速度保持在 100ms 内。
总结与效果
- 系统能在高峰期支撑几千 QPS的并发,座位信息实时更新,用户体验稳定流畅;
- Redis命中率达 95%,数据库压力控制在原来的10%;
- 前端延迟:高并发时保持在 100ms 左右;
- 数据一致性:通过 Lua 脚本与版本号保证无超卖。
Redis
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
@Service
public class RedisService {
@Autowired
private StringRedisTemplate redisTemplate;
// 获取索引版本号(seat:idx:{ROOMID|YYYYMMDD|SLOT})
public String getVersion(String roomId, String date, String slot) {
String idxKey = getIdxKey(roomId, date, slot);
return redisTemplate.opsForValue().get(idxKey);
}
// 设置索引版本号(seat:idx:{ROOMID|YYYYMMDD|SLOT})
public void setVersion(String roomId, String date, String slot, String version) {
String idxKey = getIdxKey(roomId, date, slot);
redisTemplate.opsForValue().set(idxKey, version);
}
// 获取快照数据(seat:data:{ROOMID|YYYYMMDD|SLOT}:v{VER})
public String getSnapshot(String roomId, String date, String slot, String version) {
String dataKey = getDataKey(roomId, date, slot, version);
return redisTemplate.opsForValue().get(dataKey);
}
// 设置快照数据(seat:data:{ROOMID|YYYYMMDD|SLOT}:v{VER})
public void setSnapshot(String roomId, String date, String slot, String version, String data) {
String dataKey = getDataKey(roomId, date, slot, version);
redisTemplate.opsForValue().set(dataKey, data);
}
// 获取重建锁(lock:rebuild:{ROOMID|YYYYMMDD|SLOT})
public boolean acquireLock(String roomId, String date, String slot) {
String lockKey = getLockKey(roomId, date, slot);
return Boolean.TRUE.equals(redisTemplate.opsForValue().setIfAbsent(lockKey, "LOCKED", 3000));
}
// 释放重建锁
public void releaseLock(String roomId, String date, String slot) {
String lockKey = getLockKey(roomId, date, slot);
redisTemplate.delete(lockKey);
}
// 生成 key(索引版本键)
private String getIdxKey(String roomId, String date, String slot) {
return "seat:idx:{" + roomId + "|" + date + "|" + slot + "}";
}
// 生成 key(快照键)
private String getDataKey(String roomId, String date, String slot, String version) {
return "seat:data:{" + roomId + "|" + date + "|" + slot + "}:v" + version;
}
// 生成 key(重建锁键)
private String getLockKey(String roomId, String date, String slot) {
return "lock:rebuild:{" + roomId + "|" + date + "|" + slot + "}";
}
}Lua
为了避免并发冲突,我们利用 Redis 的 Lua 脚本来实现原子操作。这样可以保证在操作过程中,座位的状态与版本号的更新是 一致性保证 的。
操作:在 Redis 内部执行一个 Lua 脚本,完成以下操作:
- 读取座位的当前状态;
- 判断是否可以更新(例如,当前状态是否是
free); - 更新座位状态,递增版本号;
- 返回更新结果。
public String updateSeatAndGetNewVersion(String roomId, String date, String slot, String seatId, String currentStatus, String newStatus, String currentVersion) {
String idxKey = getIdxKey(roomId, date, slot);
String dataKey = getDataKey(roomId, date, slot, currentVersion);
String lockKey = getLockKey(roomId, date, slot);
// Lua 脚本原子执行
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
"redis.call('set', KEYS[2], ARGV[2]); " +
"redis.call('incr', KEYS[3]); " +
"return 1; " +
"else return 0; end";
Long result = redisTemplate.execute(
RedisScript.of(luaScript, Long.class),
Arrays.asList(idxKey, dataKey, lockKey),
currentStatus, newStatus, currentVersion
);
return result != null && result == 1 ? "Updated successfully" : "Update failed";
}Redis位图
如果一天有多个时段(例如 10 个时段),你可以使用 位图(Bitmap) 来存储每个座位在各个时段的预约状态。这样,座位的状态就可以通过一个 位图 来表示每个时段的预约情况,极大地优化了存储和操作效率。
操作:
- 设置座位状态(位图):
SETBIT seat:doc:{room|date}:{seatId} {slotIndex} {status} - 获取座位状态(位图):
GETBIT seat:doc:{room|date}:{seatId} {slotIndex}
// 设置座位状态,假设时段从 0 到 9,共 10 个时段
public void setSeatStatus(String roomId, String date, String seatId, int slotIndex, boolean isBooked) {
String key = getSeatDocKey(roomId, date, seatId);
// Redis SETBIT:slotIndex 从 0 开始,isBooked true = 1,false = 0
redisTemplate.opsForValue().setBit(key, slotIndex, isBooked ? 1 : 0);
}
// 获取座位的状态,假设要查询第 3 个时段的状态
public boolean getSeatStatus(String roomId, String date, String seatId, int slotIndex) {
String key = getSeatDocKey(roomId, date, seatId);
// Redis GETBIT:返回的是 0 或 1
return redisTemplate.opsForValue().getBit(key, slotIndex);
}锁的作用
获取锁
在变更某个时段的座位数据时,首先会尝试获取重建锁,确保 只有一个请求 能进行数据修改。如果锁已被占用,其他请求就无法修改数据,必须等待或者失败。
SETNX lock:rebuild:{A101|20250929|AM} "LOCKED"更新数据
当请求成功获得锁后,系统才允许它对该时段的数据进行修改。这个过程包括:
- 读取当前的 版本号(通过
seat:idx)。 - 读取当前版本的座位数据(通过
seat:data:{A101|20250929|AM}:v{VERSION})。 - 更新座位数据,创建新版本的快照。
- 更新版本号(
seat:idx)并存储新的快照数据。
释放锁
数据更新完成后,客户端会 释放锁,允许其他请求获取锁并进行更新操作。
DEL lock:rebuild:{A101|20250929|AM}8.2 项目案例分析-Echarts图展示优化
以及在第一个小程序中需要用到echart展示ws实时获取的数据,如何保证大量数据稳定更新,以及数据变化过快时的稳定显示
前端确实不一定要完全被动地接收后端传过来的数据。我们可以通过前端的虚拟列表或者可视区域的计算,来决定当前应该展示哪些数据。”
“具体来说,前端会根据用户的滚动或者视口范围,动态计算出当前需要展示的数据片段。后端虽然会提供数据流,但前端只会在需要的时候去请求或者渲染对应的数据。这样就能避免一次性把所有数据都加载出来,而是按需加载。”
后端ws发送数据之间做好信息聚合,确定好最短时长区间,展示一部分数据。
8.3 项目案例分析-图书热榜优化
基础分
单书总分 = 单书借阅分$\times$借阅分比例 + 单书评分$\times$评分比例
单书借阅分 = 01归一化 ( 单书借阅次数 / 借阅总次数 )
单书评分 = 所有人对该书评分的均值
Redis存储,7天TTL
问题
假如有一本书最新才上架,但是直接衰减又得考虑经典流传千古。或者说假如有本新发布的书最近很火,需要急推
改进
近期单书总分 = 按照30天(或7/14天)计算单书总分
final = α * 单书总分 + (1-α) * 近期单书总分
新书冷启动补偿
上架 ≤ T 天(如 30 天)的图书,给一个新书加分:boost_new = β * g(days_since_publish),如 g(d)=max(0, 1 - d/T) 线性下降或指数下降;β 可取 0.05~0.15(占比不大但够“扶上榜”)。
final += boost_new
8.4 项目案例分析-并发处理
1. 网关限流
首先,做好 网关限流 是应对请求风暴的第一步。通过限流,可以控制进入系统的请求数量,避免系统瞬间承受过大的压力。限流的核心目的是保证系统的稳定性,避免流量过大导致的崩溃或严重延迟。你可以在网关层设置请求的最大阈值,使用算法如令牌桶或漏桶等。
2. 消息队列
当请求量过大时,消息队列 可以作为缓冲区,将请求暂存下来,让后端服务逐步处理。这种方式可以减轻服务器的负载,特别是对于一些不需要即时响应的请求(如数据计算、存储更新等),可以通过将其发送到队列中,后台系统按顺序或延时处理。
例如,Kafka、RabbitMQ 或 RocketMQ 等消息队列可以很好地帮助你应对请求过载,将高并发请求按需处理,避免后端系统被压垮。
3. 均衡负载
负载均衡 的确是非常重要的一步,保证请求流量均匀地分配到多个后端服务实例上。具体来说:
- 同一后端服务部署到多台服务器:可以通过负载均衡将来自客户端的请求均匀地分发到不同的后端服务器上,这样每个服务器的负载不会过高,确保系统的可伸缩性和高可用性。这种方式可以有效地提高系统的承载能力。
- 一个服务复制多份:这是水平扩展的核心概念,通常我们会将服务部署为多个副本,然后通过负载均衡策略(如轮询、加权轮询、最小连接数等)将请求分发到不同的服务实例上。如果某个实例过载或者宕机,负载均衡器会自动将流量转移到健康的实例。
负载均衡策略可以采用软负载均衡(例如使用 Nginx 或 HAProxy)或硬负载均衡设备(例如 F5)进行流量管理。
4. Redis
Redis 在应对高并发时扮演着至关重要的角色,特别是在读多写少的场景下,Redis 可以大大减少数据库查询的压力,提高系统的响应速度。你可以将一些高频访问的数据(如用户信息、缓存查询结果等)存储在 Redis 中,以减少数据库的直接访问。
同时,Redis 还可以做为 消息队列 的一部分,帮助异步处理请求。
5. 熔断机制
熔断机制 用于在系统压力过大时保护关键服务不被压垮。比如,如果某个服务或组件的失败率超过了阈值,熔断器就会自动切断该服务的请求流,避免错误传播。这样,当后端系统恢复正常时,熔断器会自动恢复连接。
常见的熔断器实现工具如 Hystrix 和 Resilience4j,可以帮助你实现服务的稳定性和容错性。
9. 软考
9.1 软考笔记
短除法、真值、机器数(有符号数(原反补移,-0的补码,补码整数范围)、无符号数)、海明码
10. 面经
10.1 面经-南瑞继保【软开】一面
让我介绍了两个项目,根据项目提了点简单的问题,比如微信登陆怎么做的、科研项目有没有考虑做通信效率之类的,然后就是反问了,一共20来分钟
反问的时候问了下加班情况,说一般周六都是加班的,周中晚上也会“集中学习”(
据说只有一面,7天出结果
2
面试官会加你联系方式线上面试,问的不难,看内容主要也是需要 java 后端、数据库,是南瑞继保的另一个部门,问了面试官部门具体情况,说是加班会少很多,强度是隔壁的一半基本,不怎么出差,待遇低点。
3 南瑞继保2023校招 开发工程师
自我介绍
项目经历
项目难点
第二个项目内容
JPA(Java持久化规范:Hibernate全ORM框架)
图数据结构设计(邻接表和邻接矩阵)
图数据库相关(关系型数据库 (MySQL, PostgreSQL)、图数据库 (Neo4j, NebulaGraph))
Redis作用
项目分工
Shiro框架
八股
内存泄露怎么排除
先看内存大小是否过大,然后生成内存快照文件,通过mat打开文件检查链路树,寻找到占用内存较大的对象,判断是静态变量、缓存或者threadlocal是否释放
Spring和SpringBoot差别
Spring Boot 是 Spring 的“扩展”。它的核心目的是让基于 Spring 的开发变得更快、更简单、更自动化。
Spring是一个强大的Java开发框架,提供了一系列的应用模块支持需求,包括依赖注入、面向切片编程、事务管理、web应用程序开发等。
Springboot简化了Spring应用程序的开发和部署,相当于全自动洗衣机,特别是用于微服务和快速开发的应用程序。
Springboot的优势:
自动配置
Spring Boot 通过Auto-Configuration来减少开发人员的配置工作。我们可以通过一个starter就把依赖导入,启动时会根据项目中引入的 Jar 包,自动为项目配置所需的 Bean。从而告别繁琐配置:无需手动写 @Configuration或 XML 来配置 DataSource、TransactionManager、MVC 等组件。
内嵌Web服务器
Spring Boot内置了常见的Web服务器(如Tomcat、Jetty),这意味着您可以轻松创建可运行的独立应用程序,而无需外部Web服务器。
约定大于配置
SpringBoot中有很多约定大于配置的思想的体现,通过一种约定的方式,来降低开发人员的配置工作。如他默认读取spring.factories来加载Starter、读取application.properties或application.yml文件来进行属性配置等
Maven生命周期
clean default site
集合类
Collection(单列集合)**:存储一组独立的元素。List(列表):有序、可重复的集合。元素有索引(类似数组下标)。Set(集):无序、不可重复的集合。保证元素唯一性(依赖equals()和hashCode())。Queue(队列):先进先出 (FIFO)** 的集合。主要用于模拟队列行为(如任务调度)。Deque(双端队列):扩展了Queue,允许从两端插入和移除元素。Map(双列集合)**:存储键值对 (Key-Value Pair)。键 (Key) 不可重复(依赖equals()和hashCode()),值 (Value) 可重复**。
ArrayList和LinkedList
虽然链表节点本身的插入操作是 O(1),但在任意位置(如第 i 个位置)插入元素时,必须先遍历到该位置,这个查找过程是 O(n)。
SpringCloud
过滤器使用
Spring MVC 的拦截器 (HandlerInterceptor) 工作于 DispatcherServlet 之后、Controller 之前。但 WebSocket 的握手请求由 Servlet 容器直接处理(如 Tomcat 的 WsServerContainer),根本不经过 DispatcherServlet,因此拦截器完全感知不到该请求。
package com.example.workspace.component;
import com.example.workspace.security.JWTAuthenticationToken;
import com.example.workspace.service.TokenService;
import jakarta.servlet.FilterChain;
import jakarta.servlet.ServletException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.util.AntPathMatcher;
import org.springframework.web.filter.OncePerRequestFilter;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
//HTTP 请求的 JWT 认证过滤器,确保每个 HTTP 请求只被过滤一次
public class JWTAuthenticationFilter extends OncePerRequestFilter {
@Autowired
private TokenService tokenService;
// 定义需要跳过的路径
private static final List<String> SHOULD_NOT_FILTER = Arrays.asList( // 数组转list,
// 它返回的 List 并不是标准的 ArrayList,而是一个基于原始数组的视图(View)
// 固定长度,底层仍然是数组,因此不能增删元素,没有实现 add/remove 等方法。
// 通过 set 方法或直接操作原数组
"/api/users/login",
"/api/token/validate",
"/api/reservations/getAll",
"/api/users/register",
"/v3/**",
"/swagger-ui.html",
"/swagger-ui/**",
"/api/books/hot-weekly"
);
@Override
protected boolean shouldNotFilter(HttpServletRequest request){
// return SHOULD_NOT_FILTER.stream() // List<String>转换为 Java 流(Stream<String>),以便使用流式操作(如过滤、映射、匹配等)。
// .anyMatch(path -> request.getServletPath().equals(path));// Lambda 表达式,左侧是参数(path),右侧是表达式
// // anyMatch检查流中是否至少有一个元素满足给定条件,Lambda表示流中path元素满足
// // 变量名可以自定义, anyMatch 是一个终端操作,执行后会关闭流。再次使用stream.count(); // ❌ 报错:流已被消费
// // 流的设计初衷是一次性、单向处理数据(类似迭代器),目的是为了高效处理大数据集,避免重复遍历带来的性能问题。
AntPathMatcher pathMatcher = new AntPathMatcher(); //AntPathMatcher 来支持通配符匹配
// Spring 框架中用于处理路径模式匹配 的工具类
return SHOULD_NOT_FILTER.stream()
.anyMatch(pattern -> pathMatcher.match(pattern, request.getServletPath()));
}
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
//request封装了客户端发送的 HTTP 请求信息,response封装了即将发送给客户端的 HTTP 响应信息(状态码、响应头、响应内容)
String token = request.getHeader("token");
if(shouldNotFilter(request)) {
filterChain.doFilter(request, response);
return;
}
if (token == null) {
// filterChain.doFilter(request, response); // filterChain代表过滤器链,用于将请求传递给下一个过滤器或目标资源,doFilter 放行
response.setContentType("application/json");
response.getWriter().write("{\"code\": 401, \"message\": \"Invalid Token\"}");
return;
}
boolean isValid = tokenService.validateToken(token);
System.out.println("doFilterInternal "+isValid);
if (isValid) {
String username = tokenService.extractUsername();
// 创建认证对象并标记为已认证
JWTAuthenticationToken auth = new JWTAuthenticationToken(username, token);
auth.setAuthenticated(true); // 关键:仅在验证通过后设置.这个是处理 jwt 过滤器验证通过
// 下面是处理 Spring Security 授权
SecurityContextHolder.getContext().setAuthentication(auth); // SecurityContextHolder设置之后才能通过授权认证
// SecurityContextHolder.getContext().getAuthentication().getName()注册为上下文之后可以直接调用
filterChain.doFilter(request, response);
} else {
response.setStatus(HttpServletResponse.SC_UNAUTHORIZED);
response.getWriter().write("Invalid JWT Token");
}
}
// 如果使用拦截器
// @Component
// public class AuthInterceptor implements HandlerInterceptor {
// @Override
// public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
// String token = request.getHeader("token");
// if (!validateToken(token)) {
// response.setStatus(401);
// return false; // 拦截请求
// }
// return true;
// }
// }
}
// ----------------------------------------------------
// No-op
// WebSocket 握手成功完成后被调用(即客户端和服务器已建立 WebSocket 连接)
// 记录握手成功的日志。
// 释放握手前占用的资源。
// 发送通知或更新状态(例如标记用户在线)
}
// 过滤器在先,普通拦截器在后,都是处理http请求
// 过滤器可以过滤握手的http请求,tcp握手在传输层(Layer 4)这个是应用层(Layer 7)
// WebSocket 连接建立前的握手也是一个 HTTP 请求 (带有 Upgrade: websocket 头),只是它的目的是升级协议
// 过滤器可以过滤该 HTTP 请求,并修改请求或响应。
// 普通拦截器可以把bean装配进来
// 过滤器是 Servlet 规范的一部分,处理所有 HTTP 请求(包括 WebSocket 握手请求),但无法处理 WebSocket 协议数据帧,可以用消息拦截器
// (例如记录日志、权限校验),需使用 WebSocketHandler 或 STOMP 的消息拦截器(如 ChannelInterceptor)。
// 握手拦截器在握手时拦截,普通拦截器做不到
// 过滤器通吃,握手时也能过滤Redis数据结构
4 软件研发
一.项目&实习
1.数据怎么来的,详解整个毕设思路方法 结果
2.性能指标怎么评价的
3.数据处理方面做了哪些工作
4.用 SD造的数据有没有测试验证集效果如何
5.为什么选取这个模型,优缺点,改进工作
6.模型怎样在npu上做适配的
7.讲讲哪个项目遇到的最大困难点,如何解决的
8.有哪些模型落地部署的优化思路
二.聊天
8.已有的 offer开多少,为什么不选择待私企
9.期望薪资 个人信息 学校获奖比赛
5 自动控制
1、自我介绍
2、挑一个简历项目展开讲,介绍项目?怎么做的?遇到什么问题?如何解决?
3、根据项目内容问了几个针对性的问题
4、闲聊了一下实习单位、学校其他情况
5、对南瑞继保有什么了解
没有问专业课,整体简历向,不算压力面,
10.2 八股
JVM/java
1.简述一下JVM的内存模型
2.堆和栈的区别
3.什么时候会触发FulI GC
4.什么是java虚拟机?为什么java被称作是“平台无关的编程语言’
5.java内存结构
6.说说对象分配规则
7.描述一下JVM加载class文件的原理机制?
8.说说内存泄漏和内存溢出,怎么解决?
10.JVM的永久代中会发生垃圾回收吗?
11.java数据结构介绍
MySQL篇
1、数据库的三范式是什么
2、MySOL数据库引擎有哪些
3、说说InnoDB与MyISAM的区别
4、数据库的事务
5、索引是什么
6、SQL优化手段有哪些
7、简单说一说drop、delete与truncate的区别
8、什么是视图
9、什么是内连接、左外连接、右外连接?
10、并发事务带来哪些问题?
11.SQL注入
SpringBoot篇
1、为什么要用SpringBoot
2、Spring Boot 的核心注解是哪个?它主要由哪几个注解组成
3、运行Spring Boot有哪几种方式?
4、如何理解 Spring Boot 中的 Starters ?
5、如何在Spring Boot启动的时候运行一些特定的代码?
6、Spring Boot 需要独立的容器运行吗?
7、Spring Boot中的监视器是什么?
8、如何使用Spring Boot实现异常处理?
10、springboot常用的starter有哪些
多线程&并发篇:
1、说说Java中实现多线程有几种方法
2、如何停止一个正在运行的线程
3、notify()和notifyAll()有什么区别?
4、sleep()和wait()有什么区别?
5、volatile 是什么?可以保证有序性吗?
6、Thread 类中的start()和 run()方法有什么区别?
7、为什么wait, notify 和 notifyAll这些方法不在thread类里面?
8、为什么wait和notify方法要在同步块中调用?
9、Java中interrupted和isInterrupted方法的区别?
10、Java中synchronized 和 ReentrantLock 有什么不同?
中间件
redis
什么是redis,作用是什么?什么场景用redis比较好?有哪些数据结构、持久化、延迟双删、雪崩
MQ
三个MQ的区别,举一个实际使用的例子
SpringCloud篇
1、什么是SpringCloud
2、什么是微服务
3、SpringCloud有什么优势
4、什么是服务熔断?什么是服务降级?
5、Eureka和zookeeper都可以提供服务注册与发现的功能,请说
说两者的区别?
6、SpringBoot和SpringCloud的区别?
7、负载平衡的意义是什么?
8、什么是Hystrix?它如何实现容错?
9、什么是Hystrix断路器?我们需要它吗?
10、说说 RPC的实现原理
MyBatis篇
1、什么是MyBatis
2、说说MyBatis的优点和缺点
3、#{}和${}的区别是什么?
4、当实体类中的属性名和表中的字段名不一样,怎么办?
5、Mybatis是如何进行分页的?分页插件的原理是什么?
6、Mybatis是如何将sql执行结果封装为目标对象并返回的?都有
7、如何执行批量插入?
8、Xml映射文件中,除了常见的select|insert|update|delete 标签之外,还有什么
9、MyBatis实现一对一有几种方式?具体怎么操作的?
10、MyBatis是否支持延迟加载?如果支持,它的实现原理是什么?
Spring篇
1、什么是spring?
2、你们项目中为什么使用Spring框架?
3、Autowired和Resource关键字的区别?
4、依赖注入的方式有几种,各是什么?
5、讲一下什么是Spring
6、说说你对Spring MVC的理解
7、SpringMVC常用的注解有哪些?
8、谈谈你对Spring的AOP理解
9、Spring AOP和AspectJ AOP有什么区别?
10、说说你对Spring的IOC是怎么理解的?
分布式篇
1、分布式幂等性如何设计?
2,简单一次完整的 HTTP 请求所经历的步骤?
3、说说你对分布式事务的了解
4、你知道哪些分布式事务解决方案?
5、什么是二阶段提交?
6、什么是三阶段提交?
7、什么是补偿事务?
8、消息队列是怎么实现的?
9、那你说说Sagas事务模型
10、分布式ID生成有几种方案?



