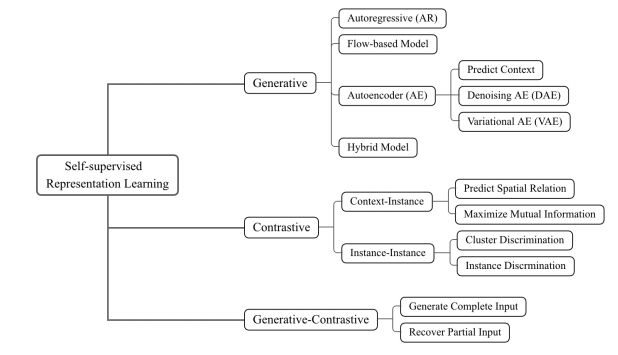
The defects of heavy dependence on manual labels and vulnerability to attacks forced people to focus on self-supervised learning rather than deep supervised learning, which has three categories: generative, contrastive, and generative-contrastive (adversarial).
• Generative: train an encoder to encode input x into an explicit vector z and a decoder to reconstruct x from z (e.g., the cloze test, graph generation)
• Contrastive: train an encoder to encode input x into an explicit vector z to measure similarity (e.g., mutual information maximization, instance discrimination)
• Generative-Contrastive (Adversarial): train an encoder-decoder to generate fake samples and a discriminator to distinguish them from real samples (e.g., GAN)
Their main difference lies in model architectures and objectives. A detailed conceptual comparison is shown in Fig. 4. Their architectures can be unified into two general components: the generator and the discriminator, and the generator can be further decomposed into an encoder and a decoder. Different things are:
For latent distribution z: in generative and contrastive methods, z is explicit and is often leveraged by downstream tasks; while in GAN, z is implicitly modeled.
For discriminator: the generative method does not have a discriminator while GAN and contrastive have. Contrastive discriminator has comparatively fewer parameters (e.g., a multi-layer perceptron with 2-3 layers) than GAN (e.g., a standard ResNet [53]).
For objectives: the generative methods use a reconstruction loss, the contrastive ones use a contrastive similarity metric (e.g., InfoNCE), and the generative-contrastive ones leverage distributional divergence as the loss (e.g.,JS-divergence, Wasserstein Distance).
This survey will take a comprehensive look at the recent developing self-supervised learning models and discuss their theoretical soundness, including frameworks such as Pre-trained Language Models (PTM), Generative Adversarial Networks (GAN), autoencoders and their extensions, Deep Infomax, and Contrastive Coding. An outline slide is also provided.
We can its features as:
• Obtain “labels” from the data itself by using a “semi-automatic” process.
• Predict part of the data from other parts.
Self-supervised learning can be viewed as a branch of unsupervised learning since there is no manual label involved. However, narrowly speaking, unsupervised learning concentrates on detecting specific data patterns, such as clustering, community discovery, or anomaly detection, while self-supervised learning aims at recovering, which is still in the paradigm of supervised settings.
There exist several comprehensive reviews related to Pre-trained Language Models, Generative Adversarial Networks, autoencoders, and contrastive learning for visual representation. However, none of them concentrates on the inspiring idea of self-supervised learning itself. In this work, we collect studies from natural language processing, computer vision, and graph learning in recent years to present an up-to-date and comprehensive retrospective on the frontier of self-supervised learning. To sum up, our contributions are:
• We provide a detailed and up-to-date review of self-supervised learning for representation. We introduce the background knowledge, models with variants, and important frameworks. One can easily grasp the frontier ideas of self-supervised learning.
• We categorize self-supervised learning models into generative, contrastive, and generative-contrastive (adversarial), with particular genres inner each one. We demonstrate the pros and cons of each category.
• We identify several open problems in this field, analyze the limitations and boundaries, and discuss the future direction for self-supervised representation learning.
Several open problems and future directions in self-supervised learning for representation are still needed to be discussed:
Theoretical Foundation
Transferring to downstream tasks
Transferring across datasets
Exploring potential of sampling strategies
Early Degeneration for Contrastive Learning